概念
1.线性回归(Linear Regression)
用一条曲线对数据点进行拟合,得到最佳拟合曲线,这个拟合过程叫做回归。回归问题的求解过程就是通过训练分类器采用最优化算法来寻找最佳拟合参数集。
当拟合曲线为一条直线时,就是线性回归。其中,“线性”是指特征和结果都是线性的,即不大于一次方,每个分量表示一个特征,向量表示为:
\[h_{\theta }(x)=\theta ^{T}x\]h=hypothesis,是特征函数的估计表达式,由于求解一个含有参数众多的线性矩阵方程,需要建立足够的约束条件才能得到唯一解。
而实际上大多数情况下都只能求解超定方程组的近似最优解,即满足使得估计值与实际值的方差最小时的参数解,可以表示为:
\[j(\theta_{0},\theta_{1},,,\theta_{n})=\frac{1}{2}\sum_{i=1}^{m}(h_{\theta }{x^{(i)}})-({y^{(i)}})^{2}\]其中
m:训练集的样本个数
n:训练集的特征个数(通常每行数据为一个x(0)=1与n个x(i) (i from 1 to n)构成,所以一般都会将x最左侧加一列“1”,变成n+1个特征)
x:训练集(可含有任意多个特征,二维矩阵,行数m,列数n+1,即x0=1与原训练集结合)
y:训练集对应的正确答案(m维向量,也就是长度为m的一维数组)
h(x):模型对应的函数(返回m维向量)
$\theta$:h的初始参数(常为随机生成。n+1维向量)
2.代价函数(Cost Function)
计算建立的模型对真实数据的误差(Modeling Error)。误差越低,模型对数据拟合度越高.
找到一组参数$\theta$使得代价$\min j_{\theta }$最小.
3.最小化J($\theta$)的方法
1)最小二乘法(min square)
\[Intuition:if 1D(\alpha \theta \in \mathbb{R})\] \[J(\theta )=a\theta ^{2}+b\theta+c\]要求上面的代价方程找出$\theta$最小值,本质上就是对二次函数直接求导计算导数为0处即为最小值。对于多参数的线性回归,只要求偏导即可获得每个$\theta$值到达全局最优解。
在矩阵运算中,假设我们的训练集矩阵为X,结果向量为y,则$\theta$可以分别求偏导数直接得出。
若X是列满秩的,则有公式:
\[\theta =(X^{T}X)^{-1}X^{T}\overrightarrow{y}\]这个公式即最小二乘法,是从求导推导出来的。推导过程
显然地,若矩阵不可逆,就不能用这个方法求解了(出现这个情况的可能原因是1.各个特征不独立、有关联;2.特征数量大于所给训练集样本个数)。此时就需要乃至下面的方法。
2)梯度下降法(Gradient Descent)
梯度下降法(gradient descent)是一个最优化算法,常用于机器学习和人工智能当中用来递归性地逼近最小偏差模型。顾名思义,梯度下降法的计算过程就是沿梯度下降的方向求解极小值(也可以沿梯度上升方向求解极大值)。
本质上是根据偏导数,步长/最佳学习率,更新参数,收敛损失函数。
梯度下降法是按下面的流程进行的:
-
首先对θ赋值,这个值可以是随机的,也可以让θ是一个全零的向量。
-
改变θ的值,使得J(θ)按梯度下降的方向进行减少。
(1). 梯度
在微积分里面,对多元函数的参数求∂偏导数,把求得的各个参数的偏导数以向量的形式写出来,就是梯度。
比如函数f(x,y), 分别对x,y求偏导数,求得的梯度向量就是$(∂f/∂x, ∂f/∂y)^{T}$,简称grad f(x,y)或者▽f(x,y)。对于在点(x0,y0)的具体梯度向量就是$(∂f/∂x0, ∂f/∂y0)^{T}$.或者▽f(x0,y0),如果是3个参数的向量梯度,就是$(∂f/∂x, ∂f/∂y,∂f/∂z)^{T}$,以此类推。
梯度向量从几何意义上讲,就是函数变化增加最快的地方。具体来说,对于函数f(x,y),在点(x0,y0),沿着梯度向量的方向就是$(∂f/∂x0, ∂f/∂y0)^{T}$的方向是f(x,y)增加最快的地方。沿着梯度向量的方向,更加容易找到函数的最大值。反过来说,沿着梯度向量相反的方向,也就是 $-(∂f/∂x0, ∂f/∂y0)^{T}$的方向,梯度减少最快,也就是更加容易找到函数的最小值。
(2)梯度下降算法
Repeat {
\[\theta _{j}:=\theta _{j}-a\frac{\partial }{\partial \theta _{j}}J(\theta _{0},\theta _{1}...,\theta _{n})\]}
其中 a是学习率(Learning Rate),其大小决定了每次循环中$\theta$改变的大小,决定了梯度下降步子迈多大。寻找a很关键。a小了,每次循环步子也迈的小,要很多步才能到达最低点,速度慢。a太大了,可能一下就越过了最低点,并不断一次次越过来越过去就是到不了最低点,太大了甚至可能导致循环无法收敛、甚至发散。通常可以考虑尝试这些学习率:α=0.01,0.03,0.1,0.3,1,3,10
可以看出,随着算法越来越接近局部最小值,J’越小,下降速度越慢,因此a只需是个定值,无需在靠近最小值时一起减小a。
需要注意的一点是,每个$\theta_{j}$必须是同步变换,即不能修改了theta1为新计算得的值后再计算要修改的theta2,这样计算出的theta2是基于是修改后的theta1而得到的。因此要计算出全部新theta后统一赋值。
该梯度下降算法也被称为批量梯度下降。“批量”指的是在梯度下降的每一步中,我们都用到了所有的训练样本。
(3)线性回归上的梯度下降:
Repeat{
\[\theta _{j}:=\theta _{j}-a\frac{\partial }{\partial \theta _{j}}\frac{1}{2m}\sum_{i=1}^{m}(h_{\theta }(x^{(i)})-y^{(i)})^{2}\]}
其中
\[h_{\theta }(x)=\theta ^{T}X=\theta _{0}x_{0}+\theta _{1}x_{1}+...+\theta _{n}x_{n}\](4)梯度下降的算法调优
- 算法的步长选择
步长取值取决于数据样本,可以多取一些值,从大到小,分别运行算法,看看迭代效果,如果损失函数在变小,说明取值有效,否则要增大步长。算法的步长需要多次运行后才能得到一个较为优的值。
- 算法参数的初始值选择
初始值不同,获得的最小值也有可能不同,因此梯度下降求得的只是局部最小值;当然如果损失函数是凸函数则一定可以得到最优解。由于有局部最优解的风险,需要多次用不同初始值运行算法,选择损失函数最小化的初值。
- 归一化
由于样本不同特征的取值范围不一样,可能导致迭代很慢,为了减少特征取值的影响,可以对特征数据归一化,也就是对于每个特征x,求出它的期望$\overline{x}$ 和标准差std(x),然后转化为:
\[(x−\overline{x})/std(x)\]这样特征的新期望为0,新方差为1,迭代次数可以大大加快。
(5)梯度下降算法族
- 批量梯度下降法(Batch Gradient Descent)
批量梯度下降法,是梯度下降法最常用的形式,具体做法是在更新参数时使用所有的样本来进行更新。
- 随机梯度下降法(Stochastic Gradient Descent)
随机梯度下降法和批量梯度下降法原理类似,区别在与求梯度时没有用所有的m个样本的数据,而是仅仅选取一个样本j来求梯度。
随机梯度下降法,和批量梯度下降法是两个极端,一个采用所有数据来梯度下降,一个用一个样本来梯度下降。
对于训练速度来说,随机梯度下降法由于每次仅仅采用一个样本来迭代,训练速度很快,而批量梯度下降法在样本量很大的时候,训练速度不能让人满意。对于准确度来说,随机梯度下降法用于仅仅用一个样本决定梯度方向,导致解很有可能不是最优。对于收敛速度来说,由于随机梯度下降法一次迭代一个样本,导致迭代方向变化很大,不能很快的收敛到局部最优解。
- 小批量梯度下降法(Mini-batch Gradient Descent)
小批量梯度下降法是批量梯度下降法和随机梯度下降法的折衷,也就是对于m个样本,我们采用x个样子来迭代,。通常取x=10,当然也可以根据样本的数据,可以调整这个x的值。小批量梯度下降法结合了上面两种方法的优点。
(6)梯度下降法和其他无约束优化算法的比较
在机器学习中的无约束优化算法,除了梯度下降以外,还有前面提到的最小二乘法,此外还有牛顿法和拟牛顿法。
梯度下降法和最小二乘法相比,梯度下降法需要选择步长,而最小二乘法不需要。梯度下降法是迭代求解,最小二乘法是计算解析解。如果样本量不算很大,且存在解析解,最小二乘法比起梯度下降法要有优势,计算速度很快。但是如果样本量很大,用最小二乘法由于需要求一个超级大的逆矩阵,这时就很难或者很慢才能求解解析解了,使用迭代的梯度下降法比较有优势。
梯度下降法和牛顿法/拟牛顿法相比,两者都是迭代求解,不过梯度下降法是梯度求解,而牛顿法/拟牛顿法是用二阶的海森矩阵的逆矩阵或伪逆矩阵求解。相对而言,使用牛顿法/拟牛顿法收敛更快。但是每次迭代的时间比梯度下降法长。
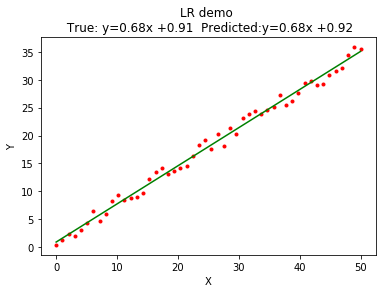
scikit-learn示例
# coding:utf-8
import numpy as np
import random
from sklearn.linear_model import LinearRegression
import matplotlib.pyplot as plt
%matplotlib inline
#构造近似于y = a * x + b 的数据集
n=50
a = random.random()
b = random.random() * 1
x = np.linspace(0,n,n)
y = [ item * a +(random.random() - 0.5) * a * 5 + b for item in x]
true_y = [ item * a for item in x]
#回归和预测
model = LinearRegression()
model.fit(np.reshape(x,[len(x),1]), np.reshape(y,[len(y),1]))
yy = model.predict(np.reshape(x,[len(x),1]))
#绘图
plt.figure()
aa = model.coef_[0][0] # 获得预测模型的参数
bb = model.intercept_[0] #获得预测模型的截距
plt.title('LR demo \n True: y='+str(a)[0:4]+'x +'+str(b)[0:4]+' Predicted:y='+str(aa)[0:4]+'x +'+str(bb)[0:4] );
plt.xlabel('X')
plt.ylabel('Y')
plt.plot(x,y,'r.') # 绘图
plt.plot(x,yy,'g-') # 绘图
plt.show() # 显示图像
版权声明:本文为博主原创文章,转载请注明出处。 旭日酒馆