flume
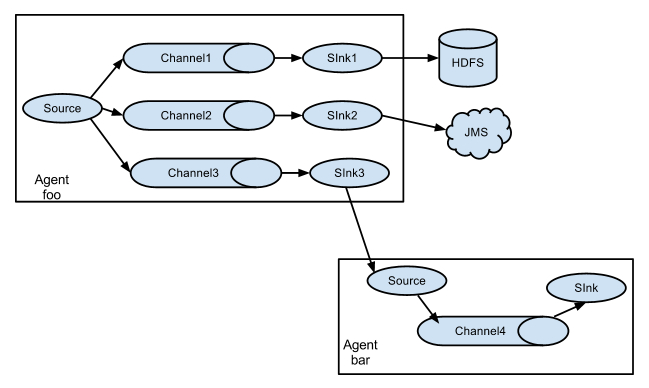
apache flume 是一个从可以收集例如日志,事件等数据资源,并将这些数量庞大的数据从各项数据资源中集中起来存储的工具/服务,或者数集中机制。flume具有高可用,分布式,配置工具,其设计的原理也是基于将数据流,如日志数据从各种网站服务器上汇集起来存储到HDFS,HBase等集中存储器中。其结构如下图所示:
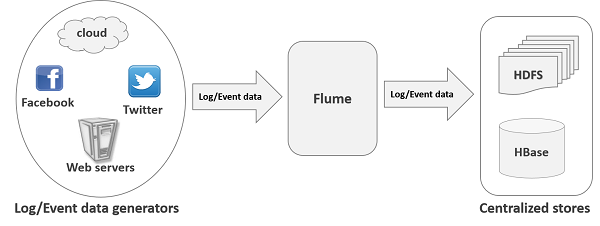
- flume数据流模型
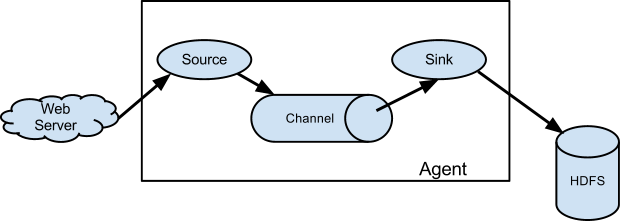
flume就是将数据从数据源(source)收集过来,flume先缓存数据(channel),再将收集到的数据送到指定的目的地(sink),最后flume删除自己缓存的数据,这样就是一个Event ,被定义为具有字节数组和可选字符串属性的数据流单元。包括 event headers、event body、event信息 。
- flume Event
事件作为flume内部数据传输的最基本单元.它是由一个转载数据的字节数组(该数据组是从数据源接入点传入,并传输给传输器,也就是HDFS/HBase)和一个可选头部构成.

- flume Agent
flume Agent 是一个(JVM)进程,用于承载Event从外部源流向下一个目标
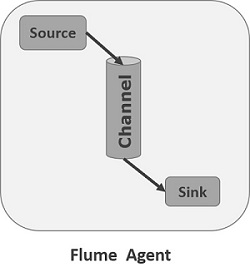
Agent 由三个核心组成
- Source source组件是专门用来收集数据的,类似生产者。消耗由外部源(如Web服务器)传递给它的Event。外部源以flume源能识别的格式向flume发送Event,flume提供多种数据接收的方式,比如Avro,Thrift,twitter1%等.
-
Avro Source:监听AVRO端口来接受来自外部AVRO客户端的事件流。利用Avro Source可以实现多级流动、扇出流、扇入流等效果。另外也可以接受通过flume提供的Avro客户端发送的日志信息。
-
Spooling Directory Source:这个Source允许你将将要收集的数据放置到”自动搜集”目录中。这个Source将监视该目录,并将解析新文件的出现。事件处理逻辑是可插拔的,当一个文件被完全读入通道,它会被重命名或可选的直接删除。要注意的是,放置到自动搜集目录下的文件不能修改,如果修改,则flume会报错。另外,也不能产生重名的文件,如果有重名的文件被放置进来,则flume会报错。
-
NetCat Source:一个NetCat Source用来监听一个指定端口,并将接收到的数据的每一行转换为一个事件。
-
HTTP Source:HTTP Source接受HTTP的GET和POST请求作为flume的事件,其中GET方式应该只用于试验。该Source需要提供一个可插拔的”处理器”来将请求转换为事件对象,这个处理器必须实现HTTPSourceHandler接口,该处理器接受一个 HttpServletRequest对象,并返回一个flume Envent对象集合。从一个HTTP请求中得到的事件将在一个事务中提交到通道中。因此允许像文件通道那样对通道提高效率。如果处理器抛出一个异常,Source将会返回一个400的HTTP状态码。如果通道已满,无法再将Event加入Channel,则Source返回503的HTTP状态码,表示暂时不可用。
-
Channel source组件把数据收集来以后临时存放在channel中,类似仓库,channal是一种短暂的存储容器,它将从source处接收到的event格式的数据缓存起来,直到它们被sinks消费掉,它在source和sink间起着一共桥梁的作用,channal是一个完整的事务,这一点保证了数据在收发的时候的一致性. 并且它可以和任意数量的source和sink链接. 支持的类型有: JDBC channel , File System channel , Memort channel等.
-
Sink sink组件类似消费者,它从channals消费数据(events)并将其传递给目标地. 目标地可能是另一个sink,也可能HDFS,HBase.
组合形式举例:
- flume插件
- Interceptors拦截器
- 用于source和channel之间,用来更改或者检查flume的events数据
-
管道选择器 channels Selectors
在多管道是被用来选择使用那一条管道来传递数据(events). 管道选择器又分为如下两种:
-
默认管道选择器: 每一个管道传递的都是相同的events
-
多路复用通道选择器: 依据每一个event的头部header的地址选择管道
- sink线程
-
用于激活被选择的sinks群中特定的sink,用于负载均衡.
-
flume的优势
-
flume可以将应用产生的数据存储到任何集中存储器中,比如HDFS,HBase
-
当收集数据的速度超过将写入数据的时候,也就是当收集信息遇到峰值时,这时候收集的信息非常大,甚至超过了系统的写入数据能力,这时候,flume会在数据生产者和数据收容器间做出调整,保证其能够在两者之间提供一共平稳的数据
-
提供上下文路由特征
-
flume的管道是基于事务,保证了数据在传送和接收时的一致性
-
flume是可靠的,容错性高的,可升级的,易管理的,并且可定制的
- flume具有的特征:
-
flume可以高效率的将多个网站服务器中收集的日志信息存入HDFS/HBase中
-
使用flume,我们可以将从多个服务器中获取的数据迅速的移交给Hadoop中
-
除了日志信息,flume同时也可以用来接入收集规模宏大的社交网络节点事件数据,比如facebook,twitter,电商网站如亚马逊,flipkart等
-
支持各种接入资源数据的类型以及接出数据类型
-
支持多路径流量,多管道接入流量,多管道接出流量,上下文路由等
-
可以被水平扩展
- flume 安装
-
解压并进入conf目录,修改文件名
mv flume-conf.properties.template flume-conf.properties
mv flume-env.sh.template flume-env.sh
- 修改配置文件
vi flume-env.sh
export JAVA_HOME=/usr/local/jdk
flume_CLASSPATH="/usr/local/hadoop/share/hadoop/hdfs/*"
- 新增文件hdfs.properties
vi hdfs.properties
LogAgent.sources = apache
LogAgent.channels = fileChannel
LogAgent.sinks = HDFS
#sources config
#spooldir 对监控指定文件夹中新文件的变化,一旦有新文件出现就解析,解析写入channel后完成的文件名将追加后缀为*.COMPLATE
LogAgent.sources.apache.type = spooldir
LogAgent.sources.apache.spoolDir = /tmp/logs
LogAgent.sources.apache.channels = fileChannel
LogAgent.sources.apache.fileHeader = false
#sinks config
LogAgent.sinks.HDFS.channel = fileChannel
LogAgent.sinks.HDFS.type = hdfs
LogAgent.sinks.HDFS.hdfs.path = hdfs://v1:9000/data/logs/%Y-%m-%d/%H #v1为hadoop master
LogAgent.sinks.HDFS.hdfs.fileType = DataStream
LogAgent.sinks.HDFS.hdfs.writeFormat=TEXT
LogAgent.sinks.HDFS.hdfs.filePrefix = flumeHdfs
LogAgent.sinks.HDFS.hdfs.batchSize = 1000
LogAgent.sinks.HDFS.hdfs.rollSize = 10240
LogAgent.sinks.HDFS.hdfs.rollCount = 0
LogAgent.sinks.HDFS.hdfs.rollInterval = 1
LogAgent.sinks.HDFS.hdfs.useLocalTimeStamp = true
#channels config
LogAgent.channels.fileChannel.type = memory
LogAgent.channels.fileChannel.capacity =10000
LogAgent.channels.fileChannel.transactionCapacity = 100
- 启动
bin/flume-ng agent --conf-file conf/hdfs.properties -c conf/ --name LogAgent -Dflume.root.logger=DEBUG,console
- 验证:
在新shell中进入监控目录/tmp/logs下,新建test.log目录并输入数据
vi test.log
#内容
test hello world
保存退出后可在之前shell看到相应输出,并且写入了hdfs.
flume和kafka的区别及联系
kafka是一个分布式的、可分区的、可复制的消息系统,维护消息队列。整体架构非常简单,是显式分布式架构,Producer、Broker和Consumer都可以有多个。Producer,consumer实现kafka注册的接口,数据从Producer发送到Broker,Broker承担一个中间缓存和分发的作用。Broker分发注册到系统中的Consumer。Broker的作用类似于缓存,即活跃的数据和离线处理系统之间的缓存。客户端和服务器端的通信,是基于简单、高性能、且与编程语言无关的TCP协议。
flume是一个分布式、可靠、高可用的海量日志采集、聚合和传输的日志收集系统。支持在日志系统中定制各类数据发送方,用于收集数据;同时,flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
flume定位于日志采集,数据通道。线上数据一般主要是落地文件或者通过socket传输给另外一个系统。这种情况下,很难推动线上应用或服务去修改接口,直接向kafka里写数据。这时就需要flume这样的系统帮你去做传输。
kafka定位为消息中间件系统,可以理解为一个cache系统。kafka设计使用了硬盘append方式,不同系统之间融合往往数据生产/消费速率不同,这时可以在这些系统之间加上kafka。例如线上数据需要入HDFS,线上数据生产快且具有突发性,如果直接上HDFS(kafka-consumer)可能会使得高峰时间hdfs数据写失败,这种情况可以把数据先写到kafka,然后从kafka导入到hdfs上。
总的来说,flume 是管道流方式,提供了很多的默认实现,让用户通过参数部署,及扩展API,适用于没有编程的配置解决方案,由于提供了丰富的source、channel、sink实现,各种数据源的引入只是配置变更就可实现。kafka是一个可持久化的分布式的消息队列, 适用于对数据管道的吞吐量、可用性要求都很高的解决方案,基本需要编程实现数据的生产和消费。
业界比较典型的用法是:
-
线上数据 -> flume -> kafka -> hdfs -> MR离线计算
-
线上数据 -> flume -> kafka -> storm
以下是评估两个系统的一些建议:
-
kafka 是一个通用型系统。你可以有许多的生产者和消费者分享多个主题。相反地,flume 被设计成特定用途的工作,特定地向 HDFS 和 HBase 发送出去。flume 为了更好地为 HDFS 服务而做了特定的优化,并且与 Hadoop 的安全体系整合在了一起。基于这样的结论,Hadoop 开发商 Cloudera 推荐如果数据需要被多个应用程序消费的话,推荐使用 kafka,如果数据只是面向 Hadoop 的,可以使用 flume。
-
flume 拥有许多配置的来源 (sources) 和存储池 (sinks)。然后,kafka 拥有的是非常小的生产者和消费者环境体系,kafka 社区并不是非常支持这样。如果你的数据来源已经确定,不需要额外的编码,那你可以使用 flume 提供的 sources 和 sinks,反之,如果你需要准备自己的生产者和消费者,那你需要使用 kafka。
-
flume 可以在拦截器里面实时处理数据。这个特性对于过滤数据非常有用。kafka 需要一个外部系统帮助处理数据。
-
无论是 kafka 或是 flume,两个系统都可以保证不丢失数据。然后,flume 不会复制事件。相应地,即使我们正在使用一个可以信赖的文件通道,如果 flume agent 所在的这个节点宕机了,你会失去所有的事件访问能力直到你修复这个受损的节点。使用 kafka 的管道特性不会有这样的问题。
-
flume 和 kafka 可以一起工作的。如果你需要把流式数据从 kafka 转移到 Hadoop,可以使用 flume 代理 (agent),将 kafka 当作一个来源 (source),这样可以从 kafka 读取数据到 Hadoop。你不需要去开发自己的消费者,你可以使用 flume 与 Hadoop、HBase 相结合的特性,使用 Cloudera Manager 平台监控消费者,并且通过增加过滤器的方式处理数据。
flume到kafka
采用flume作为数据的生产者,这样可以不用编程就实现数据源的引入,并采用kafka Sink作为数据的消费者,这样可以得到较高的吞吐量和可靠性。如果对数据的可靠性要求高的话,可以采用kafka Channel来作为flume的Channel使用。
flume作为消息的生产者,将生产的消息数据(日志数据、业务请求数据等)通过kafka Sink发布到kafka中。
对接配置
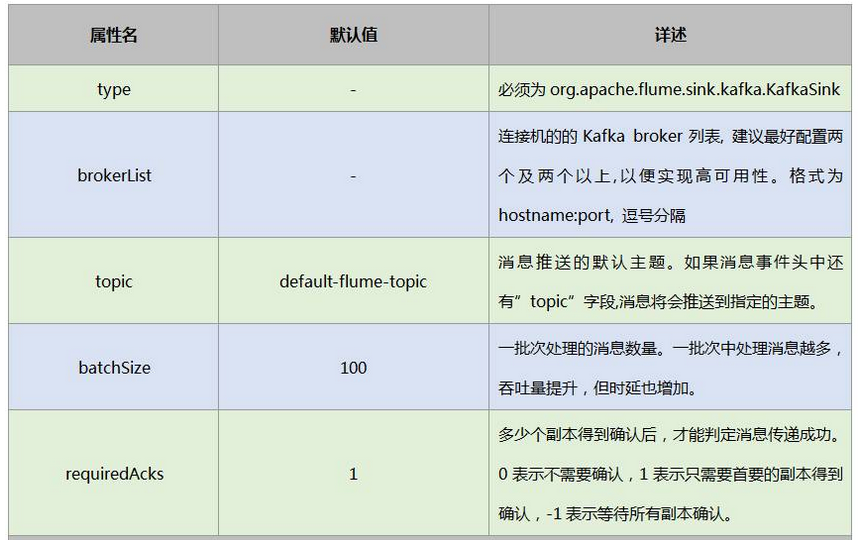
以上为必须的配置,还有一些常用可选配置:
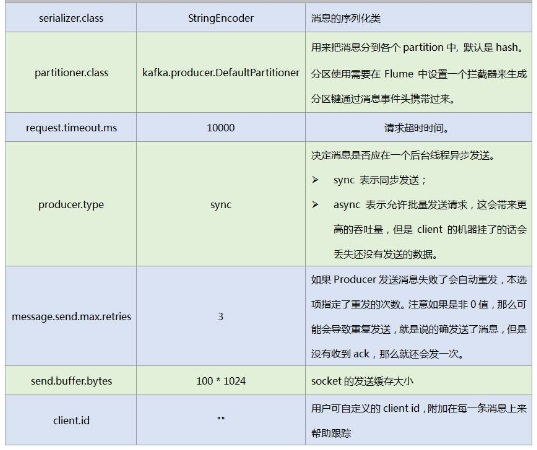
对接示例
假设现有flume实时读取/data1/logs/component_role.log的数据并导入到kafka的mytopic主题中。
-
安装环境
Zookeeper 的地址为 v1:2181 v2:2181 v3:2181
kafka broker的地址为 v1:9092 v2:9092 v3:9092
-
配置flume agent,如下修改flume配置:
gent1.sources = logsrc
agent1.channels = memcnl
agent1.sinks = kafkasink
#source section
agent1.sources.logsrc.type = exec
agent1.sources.logsrc.command = tail -F /data1/logs/component_role.log
agent1.sources.logsrc.shell = /bin/sh -c
agent1.sources.logsrc.batchSize = 50
agent1.sources.logsrc.channels = memcnl
# Each sink's type must be defined
agent1.sinks.kafkasink.type = org.apache.flume.sink.kafka.kafkaSink
agent1.sinks.kafkasink.brokerList=v1:9092 v2:9092 v3:9092
agent1.sinks.kafkasink.topic=mytopic
agent1.sinks.kafkasink.requiredAcks = 1
agent1.sinks.kafkasink.batchSize = 20
agent1.sinks.kafkasink.channel = memcnl
# Each channel's type is defined.
agent1.channels.memcnl.type = memory
agent1.channels.memcnl.capacity = 1000
- 启动flume节点
bin/flume-ng agent -c flume/conf -f conf/flume-conf.properties -n agent1 -Dflume.monitoring.type=http -Dflume.monitoring.port=10100
- 测试
动态追加日志数据,执行命令向 /data1/logs/component_role.log 添加数据:
echo "test" >> /data1/logs/component_role.log
echo "test test " >> /data1/logs/component_role.log
验证kafka数据接收结果,执行命令检查kafka收到的数据是否正确,应该可以呈现刚才追加的数据:
kafka/bin/kafka-console-consumer.sh --zookeeper v1:2181 --topic mytopic --from-beginning
参考
版权声明:本文为博主原创文章,转载请注明出处。 旭日酒馆