Flink
Apache Flink是一个用于对无边界和有边界数据流进行有状态计算的框架和分布式处理引擎。Flink设计为运行在所有常见的集群环境中,并且以内存速度和任意规模执行计算,阿里巴巴基于Flink定制化了blink自用。
任何类型的数据都是作为事件流产生的。信用卡交易事务,传感器测量,机器日志以及网站或移动应用程序上的用户交互行为,所有这些数据都生成流。数据可以作为无边界或有边界流处理。
无边界流定义了开始但没有定义结束。它们不会在生成时终止提供数据。必须持续地处理无边界流,即必须在拉取到事件后立即处理它。无法等待所有输入数据到达后处理,因为输入是无边界的,并且在任何时间点都不会完成。处理无边界数据通常要求以特定顺序(例如事件发生的顺序)拉取事件,以便能够推断结果完整性。
有边界流定义了开始和结束。可以在执行任何计算之前通过拉取到所有数据后处理有界流。处理有界流不需要有序拉取,因为可以随时对有界数据集进行排序。有边界流的处理也称为批处理。
Apache Flink擅长处理无边界和有边界数据集。在事件和状态上的精确控制使得Flink运行时能在无边界流上运行任意类型的应用程序。有界流由算法和数据结构内部处理,这些算法和数据结构专门针对固定大小的数据集而设计,从而获得优秀的性能。
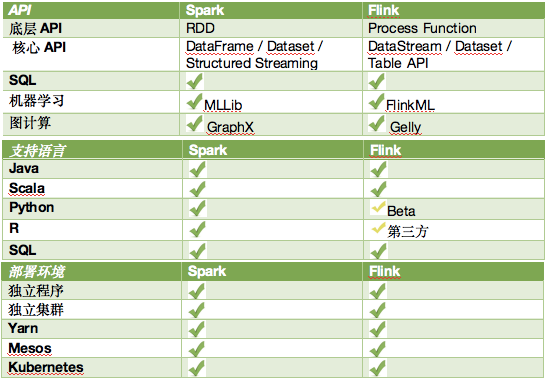
Apache Spark vs Apache Flink
对spark有所了解的可以看出,Flink和Spark两套系统都在尝试建立一个统一的平台可以运行大规模的批处理应用、流计算、图计算、机器学习等应用,Flink和Spark的目标差别并不大,他们最主要的区别在于实现的细节。
- Steaming
尽管Spark在批处理上有很大优势,但是在流处理方面依然有很大的缺陷。首先,SparkStreaming是准实时的,它处理的方式是微批处理模型。在动态调整、事物机制、延迟性、吞吐量等方面并不优秀。但是由于Spark位于Spark生态中,它可以很好的与其他应用结合,因此使用的人也不少。然而越来越多的公司发现,很多场景需要对流数据进行处理,流数据处理的价值也越来越高。如网络故障检测、欺诈行为检测等。
flink对实时流计算的支持更好,流计算需求是很多公司选择flink而非spark的重要原因。
flink的基本数据模型是数据流,及事件(Event)的序列。数据流作为数据的基本模型可能没有表或者数据块直观熟悉,但是可以证明是完全等效的。流可以是无边界的无限流,即一般意义上的流处理。也可以是有边界的有限流,这样就是批处理。
可以看出,spark设计重点在于批处理应用,用微批处理模型兼顾流计算。flink设计重点在于流计算,用有边界的有限流兼顾批处理应用。
Flink提供了基于每个事件的流式处理机制,所以可以被认为是一个真正的流式计算。它非常像storm的model。
而Spark,不是基于事件的粒度,而是用小批量来模拟流式,也就是多个事件的集合。所以Spark被认为是近实时的处理系统。
Spark streaming 是更快的批处理,而Flink Batch是有限数据的流式计算。
对大部分应用来说,准实时是可以接受的,但是也还是有很多应用需要event level的流式计算。这时就需要选择storm、flink而非Spark streaming。
- 抽象 Abstraction
Spark中,对于批处理有RDD,对于流,我们有DStream,不过内部实现都还是统一到了RDD.所有的数据表示本质上还是RDD抽象。
Flink中,对于批处理有DataSet,对于流有DataStreams。看起来和Spark类似,不同点在于:
- DataSet在运行时是表现为运行计划(runtime plans)的
在Spark中,RDD在运行时是表现为java objects的。通过引入Tungsten,这块有了些许的改变。但是在Flink中是被表现为logical plan(逻辑计划)的,类似于Spark中的dataframes。所以在Flink中使用的类Dataframe api是被作为第一优先级来优化的,相对来说在Spark RDD中就没有了这块的优化了。
Flink中的Dataset,类似Spark中的Dataframe,在运行前会经过优化。在Spark 1.6,dataset API已经被引入Spark了,也许最终会取代RDD 抽象。
- Dataset和DataStream是独立的API
在Spark中,所有不同的API,例如DStream,Dataframe都是基于RDD抽象的。但是在Flink中,Dataset和 DataStream是同一个公用的引擎之上两个独立的抽象。所以不能把这两者的行为合并在一起操作。
- 内存管理
一直到1.5版本,Spark都是试用java的内存管理来做数据缓存,明显很容易导致OOM或者gc。所以从1.5开始,Spark开始转向精确的控制内存的使用,这就是tungsten项目,从1.5开始,所有的dataframe操作都是直接作用在tungsten的二进制数据上。
Flink从开始就坚持自己控制内存。Flink把数据存在自己管理的内存空间,直接操作二进制数据。
- 语言实现
Spark是用scala来实现的,还提供了Java,Python和R的编程接口。
Flink是java实现的,提供了Scala API。
从语言的角度来看,Spark要更丰富一些。
- API
Spark和Flink都在模仿scala的collection API.所以从表面看起来,两者都很类似。两者API命名风格也类似,很方便开发者从一个引擎切换到另外一个引擎。
- SQL interface
目前Spark-sql是Spark里面最活跃的组件之一,Spark提供了类似Hive的sql和Dataframe这种DSL来查询结构化数据。
至于Flink,到目前为止,Flink Table API只支持类似DataFrame这种DSL。
- 外部数据源的整合
Spark的数据源 API是整个框架中最好的,支持NoSql db、parquet、ORC等,并且支持一些高级的操作,例如predicate push down。
Flink目前还依赖map/reduce InputFormat来做数据源聚合。
- Iterative processing
Spark对机器学习的支持较好,因为可以在Spark中利用内存cache来加速机器学习算法。但是大部分机器学习算法其实是一个有环的数据流,但是在Spark中,实际是用无环图来表示的。
一般的分布式处理引擎都不鼓励使用有环图(计算控制更难)。但是 Flink支持在runtime中的有环数据流,这样表示机器学习算法更有效而且更有效率。spark后续有可能也会支持有环数据流。
总的来说目前Spark相比Flink是一个更为成熟的计算框架,但是Spark项目开始于map/reduce的时代,不可避免得在一些设计上落后于现在流式计算逐渐成为大数据处理主流的今天。Flink的很多思路更现代,Spark社区也意识到了这一点,并且逐渐借鉴了Flink中好的设计思路,未来spark和flink估计功能会越来越接近,但又各有特点,这也是开源社区的魅力所在。
参考
版权声明:本文为博主原创文章,转载请注明出处。 旭日酒馆