Redis
Redis是什么
Redis是一种支持Key-Value等多种数据结构的存储系统。可用于缓存、事件发布或订阅、高速队列等场景。该数据库使用ANSI C语言编写,支持网络,提供字符串、哈希、列表、队列、集合结构直接存取,基于内存,可持久化。
Redis有三个主要特点,使它优越于其它键值数据存储系统
-
Redis将其数据库完全保存在内存中,仅使用磁盘进行持久化。
-
与其它键值数据存储相比,Redis有一组相对丰富的数据类型。
-
Redis可以将数据复制到任意数量的从机中。
支持的语言
支持多种编程语言:ActionScript, C, C++, C#, Chicken Scheme, Clojure, Common Lisp, Crystal, D, Dart, Erlang, Go, Haskell, Haxe, Io, Java, JavaScript (Node.js), Julia, Lua, Objective-C, OCaml, Perl, PHP, Pure Data, Python, R, Racket, Ruby, Rust, Scala, Smalltalk, Swift, and Tcl. Several client software programs exist in these languages
应用场景
-
会话缓存(最常用)
-
消息队列,比如支付
-
活动排行榜或计数
-
发布、订阅消息(消息通知)
-
商品列表、评论列表等
Redis安装和连接
sudo pacman -S redis
yaourt python-redis
然后启动redis服务器并添加开机自动启动
方法一:
# systemctl start redis
# systemctl enable redis
Created symlink /etc/systemd/system/multi-user.target.wants/redis.service → /usr/lib/systemd/system/redis.service.
方法二:
直接运行redis-server:
# redis-server
连接redis服务器,若连接远程服务器则需要:redis-cli -h host -p port -a password
$ redis-cli
127.0.0.1:6379>
至此就安装好并连接上redis服务器了.
Redis数据类型
Redis一共支持五种数据类:string(字符串)、hash(哈希)、list(列表)、set(集合)和zset(sorted set 有序集合)。
- string(字符串)
Redis最基本的数据类型,一个key对应一个value,需要注意是一个键值最大存储512MB。
常用命令:set,get,decr,incr,mget 等。
value其实不仅可以是String,也可以是数字。
常规key-value缓存应用;常规计数:微博数,粉丝数等。
127.0.0.1:6379> set key "hello"
OK
127.0.0.1:6379> get key
"hello"
127.0.0.1:6379> mset key1 "hello" key2 "world" key3 "!"
OK
127.0.0.1:6379> get key1
"hello"
127.0.0.1:6379> get key3
"!"
- hash(哈希)
Redis hash是一个键值对的集合, 是一个string类型的field和value的映射表,是表示对象的完美数据类型。在Redis中,每个哈希(散列)可以存储多达4亿个键-值对。
常用命令:hget,hset,hgetall 等。
Hash是一个string类型的field和value的映射表,hash特别适合用于存储对象。 比如我们可以Hash数据结构来存储用户信息,商品信息等等。
127.0.0.1:6379> hset redishash 1 "一"
(integer) 1
127.0.0.1:6379> hset redishash 2 "二"
(integer) 1
127.0.0.1:6379> hget redishash 1
"\xe4\xb8\x80"
127.0.0.1:6379> hget redishash 2
"\xe4\xba\x8c"
127.0.0.1:6379> hmget redishash 1 2
1) "\xe4\xb8\x80"
2) "\xe4\xba\x8c"
127.0.0.1:6379>
- list(列表)
Redis列表只是字符串列表,按插入顺序排序。可以在列表的头部或尾部添加Redis列表中的元素。列表的最大长度为2^32 - 1个元素(即4294967295,每个列表可存储超过40亿个元素)。
常用命令:lpush,rpush,lpop,rpop,lrange等
Redis list的应用场景非常多,也是Redis最重要的数据结构之一,比如微博的关注列表,粉丝列表,最新消息排行等功能都可以用Redis的list结构来实现。
Redis list的实现为一个双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销。
127.0.0.1:6379> lpush word hello
(integer) 1
127.0.0.1:6379> lpush word world
(integer) 2
127.0.0.1:6379> lrange word 0 2
1) "world"
2) "hello"
127.0.0.1:6379> llen word
(integer) 2
127.0.0.1:6379>
- set(集合)
Redis集合是唯一字符串的无序集合。 唯一值表示集合中不允许键中有重复的数据。
在Redis中设置添加,删除和测试成员的存在(恒定时间O(1),而不考虑集合中包含的元素数量)。列表的最大长度为2^32 - 1个元素(即4294967295,每组集合超过40亿个元素)。
常用命令:sadd,spop,smembers,sunion 等
set对外提供的功能与list类似是一个列表的功能,特殊之处在于set是可以自动排重的。当你需要存储一个列表数据,又不希望出现重复数据时,set是一个很好的选择,并且set提供了判断某个成员是否在一个set集合内的重要接口,这个也是list所不能提供的。
在微博应用中,可以将一个用户所有的关注人存在一个集合中,将其所有粉丝存在一个集合。Redis可以非常方便的实现如共同关注、共同喜好、二度好友等功能。
127.0.0.1:6379> sadd redis redisset
(integer) 1
127.0.0.1:6379> sadd redis redisset1
(integer) 1
127.0.0.1:6379> sadd redis redisset12
(integer) 1
127.0.0.1:6379> smembers redis
1) "redisset1"
2) "redisset12"
3) "redisset"
127.0.0.1:6379> sadd redis redisset2
(integer) 1
127.0.0.1:6379> smembers redis
1) "redisset1"
2) "redisset12"
3) "redisset"
4) "redisset2"
127.0.0.1:6379> smembers redis
1) "redisset1"
2) "redisset12"
3) "redisset"
4) "redisset2"
127.0.0.1:6379> srem redis redisset
(integer) 1
127.0.0.1:6379> smembers redis
1) "redisset1"
2) "redisset12"
3) "redisset2"
- zset(sorted set 有序集合)
string类型的有序集合,也不可重复,sorted set中的每个元素都需要指定一个分数,根据分数对元素进行升序排序,如果多个元素有相同的分数,则以字典序进行升序排序,sorted set 因此非常适合实现排名
常用命令:zadd,zrange,zrem,zcard等
和set相比,sorted set增加了一个权重参数score,使得集合中的元素能够按score进行有序排列。
127.0.0.1:6379> zadd nosql 0 001
(integer) 1
127.0.0.1:6379> zadd nosql 0 002
(integer) 1
127.0.0.1:6379> zadd nosql 0 003
(integer) 1
127.0.0.1:6379> zcount nosql 0 0
(integer) 3
127.0.0.1:6379> zcount nosql 0 3
(integer) 3
127.0.0.1:6379> zrem nosql 002
(integer) 1
127.0.0.1:6379> zcount nosql 0 3
(integer) 2
127.0.0.1:6379> zscore nosql 003
"0"
127.0.0.1:6379> zrangebyscore nosql 0 10
1) "001"
2) "003"
127.0.0.1:6379>
Redis使用
- Redis发送订阅
Redis发布订阅(pub/sub)是一种消息通信模式:发送者(pub)发送消息,订阅者(sub)接收消息。Redis 发布订阅(pub/sub)实现了消息系统,发送者(在redis术语中称为发布者)在接收者(订阅者)接收消息时发送消息。传送消息的链路称为信道。
下图是三个客户端同时订阅同一个频道:
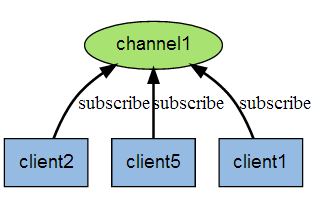
有新信息发送给频道1时,就会将消息发送给订阅它的三个客户端
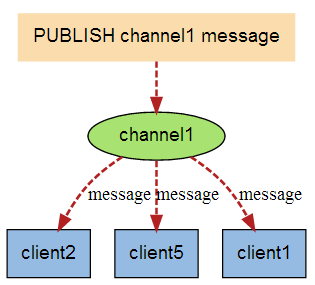
在Redis中,客户端可以订阅任意数量的信道。以下示例说明了发布用户概念的工作原理。 在以下示例中,一个客户端订阅名为“redisChat”的信道:
127.0.0.1:6379> SUBSCRIBE redisChat
Reading messages... (press Ctrl-C to quit)
1) "subscribe"
2) "redisChat"
3) (integer) 1
现在,两个客户端在名称为“redisChat”的相同信道上发布消息,并且上述订阅的客户端接收消息。
127.0.0.1:6379> PUBLISH redisChat "Redis is a great caching technique"
(integer) 1
127.0.0.1:6379> PUBLISH redisChat "Learn redis by yiibai"
(integer) 1
1) "message"
2) "redisChat"
3) "Redis is a great caching technique"
1) "message"
2) "redisChat"
3) "Learn redis by yiibai"
- Redis事务
Redis事务允许在单个步骤中执行一组命令。以下是事务的两个属性:
事务中的所有命令作为单个隔离操作并按顺序执行。不可以在执行Redis事务的中间向另一个客户端发出的请求。
Redis事务也是原子的。原子意味着要么处理所有命令,要么都不处理。
Redis事务由命令MULTI命令启动,然后需要传递一个应该在事务中执行的命令列表,然后整个事务由EXEC命令执行。
以下示例说明了如何启动和执行Redis事务:
127.0.0.1:6379> MULTI
OK
127.0.0.1:6379> SET mykey "redis"
QUEUED
127.0.0.1:6379> GET mykey
QUEUED
127.0.0.1:6379> INCR visitors
QUEUED
127.0.0.1:6379> EXEC
1) OK
2) "redis"
3) (integer) 1
- Redis脚本
Redis脚本用于使用Lua解释器来执行脚本。从Redis 2.6.0版开始内置到Redis中。使用脚本的命令是EVAL命令。
EVAL命令的基本语法:
127.0.0.1:6379> EVAL script numkeys key [key ...] arg [arg ...]
以下示例说明了Redis脚本的工作原理:
127.0.0.1:6379> EVAL "return {KEYS[1],KEYS[2],ARGV[1],ARGV[2]}" 2 key1
key2 first second
1) "key1"
2) "key2"
3) "first"
4) "second"
- Redis服务器
Redis服务器命令基本上是用于管理Redis服务器。
查看服务器信息:
127.0.0.1:6379> info
# Server
redis_version:2.8.4
redis_git_sha1:00000000
....
其他常用命令
slect #选择数据库(数据库编号0-15)
quit #退出连接
info #获得服务的信息与统计
monitor #实时监控
config get #获得服务配置
flushdb #删除当前选择的数据库中的key
flushall #删除所有数据库中的key
- Redis安全
Redis数据库可以使用安全的方案,使得进行连接的任何客户端在执行命令之前都需要进行身份验证。要保护Redis安全,需要在配置文件中设置密码。
下面的示例显示了保护Redis实例的步骤:
- 查看密码配置情况
127.0.0.1:6379> CONFIG get requirepass
1) "requirepass"
2) ""
- 设置密码 默认情况下,此属性为空,这表示还没有为此实例设置密码。您可以通过执行以下命令更改此属性。
127.0.0.1:6379> CONFIG set requirepass "password"
OK
127.0.0.1:6379> CONFIG get requirepass
1) "requirepass"
2) "password"
设置密码后,如果任何客户端运行命令而不进行身份验证,则会返回一个(error) NOAUTH Authentication required.的错误信息。 因此,客户端需要使用AUTH命令来验证。
127.0.0.1:6379> AUTH "password"
OK
127.0.0.1:6379> SET mykey "key1"
OK
127.0.0.1:6379> GET mykey
"key1"
- Redis客户端连接
Redis在配置的监听TCP端口和Unix套接字上等待和接受客户端的连接(如果已启用)。 当接受新的客户端连接时,执行以下操作 -
由于Redis使用复用和非阻塞I/O,因此客户端套接字处于非阻塞状态。
设置TCP_NODELAY选项是为了确保连接不延迟。
创建可读文件事件,以便Redis能够在套接字上读取新数据时收集客户端查询。
在Redis配置文件(redis.conf)中,有一个名称为maxclients的属性,它描述了可以连接到Redis的客户端的最大数量。
127.0.0.1:6379> config get maxclients
1) "maxclients"
2) "3984"
默认情况下,此属性设置为10000(取决于操作系统的文件描述符限制的最大数量),但可以更改此属性。
在以下示例中,我们将客户端的最大数目设置为100000,并启动服务器。
$ redis-server --maxclients 100000
- 主从配置
Redis跟MySQL一样,拥有非常强大的主从复制功能,而且还支持一个master可以拥有多个slave,而一个slave又可以拥有多个slave,从而形成强大的多级服务器集群架构。
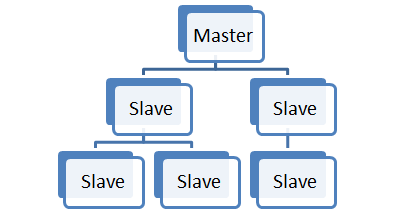
redis的主从复制是异步进行的,它不会影响master的运行,所以不会降低redis的处理性能。主从架构中,可以考虑关闭Master的数据持久化功能,只让Slave进行持久化,这样可以提高主服务器的处理性能。同时Slave为只读模式,这样可以避免Slave缓存的数据被误修改。
实际生产中,主从架构是在几个不同服务器上安装相应的Redis服务。为了测试方便,我这边的主从备份的配置,都是在我Windows 本机上测试。
-
安装两个Redis 实例,Master和Slave。将Master端口设置为6379,Slave 端口设置为6380 。bind 都设置为:127.0.0.1。
-
在Slave 实例 ,增加:slaveof 127.0.0.1 6380 配置。
-
在命令行,分别连接上Master服务器和Slave 服务器。然后在Master 写入缓存,然后在Slave 中读取。
注意:slave只能读取,不能写入数据。主从结构是为了读写分离。
- Redis持久化
Redis持久有两种方式:Snapshotting(快照),Append-only file(AOF)
Snapshotting(快照)
将存储在内存的数据以快照的方式写入二进制文件中,如默认dump.rdb中
save 900 1 :900秒内如果超过1个Key被修改,则启动快照保存
save 300 10 :300秒内如果超过10个Key被修改,则启动快照保存
save 60 10000 :60秒内如果超过10000个Key被修改,则启动快照保存
Append-only file(AOF)
使用AOF持久时,服务会将每个收到的写命令通过write函数追加到文件中(appendonly.aof)
AOF持久化存储方式参数说明:
appendonly yes #开启AOF持久化存储方式
appendfsync always#收到写命令后就立即写入磁盘,效率最差,效果最好
appendfsync everysec#每秒写入磁盘一次,效率与效果居中
appendfsync no #完全依赖OS,效率最佳,效果没法保证
- Redis管道
Redis是一个TCP服务器,支持请求/响应协议。 在Redis中,请求通过以下步骤完成:
-
客户端向服务器发送查询,并从套接字读取,通常以阻塞的方式,用于服务器响应。
-
服务器处理命令并将响应发送回客户端。
管道的基本含义是,客户端可以向服务器发送多个请求,而不必等待回复,并最终在一个步骤中读取回复。
要检查Redis管道,只需启动Redis实例,并在终端中键入以下命令。
$(echo -en "PING\r\n SET tutorial redis\r\nGET tutorial\r\nINCR
visitor\r\nINCR visitor\r\nINCR visitor\r\n"; sleep 10) | nc localhost 6379
+PONG
+OK
redis
:1
:2
:3
Shell
在上面的例子中,我们将使用PING命令检查Redis连接。这里设置了一个名称为tutorial的字符串,值为redis。 然后得到键值,并增加 visitor 数量三次。 在结果中,我们可以看到所有命令都提交到Redis一次,Redis在一个步骤中提供所有命令的输出。
这种技术的好处是大大提高了协议性能。通过管道从连接到本地主机速度增加五倍,因特网连接的至少快一百倍。
- Redis 性能测试
自带相关测试工具,下例为使用1000并发执行的性能测试:
# redis-benchmark -n 1000 -q
PING_INLINE: 24390.24 requests per second
PING_BULK: 35714.29 requests per second
SET: 35714.29 requests per second
GET: 37037.04 requests per second
INCR: 38461.54 requests per second
LPUSH: 43478.26 requests per second
RPUSH: 43478.26 requests per second
LPOP: 43478.26 requests per second
RPOP: 38461.54 requests per second
SADD: 43478.26 requests per second
HSET: 43478.26 requests per second
SPOP: 45454.55 requests per second
LPUSH (needed to benchmark LRANGE): 47619.05 requests per second
LRANGE_100 (first 100 elements): 29411.76 requests per second
LRANGE_300 (first 300 elements): 11627.91 requests per second
LRANGE_500 (first 450 elements): 7874.02 requests per second
LRANGE_600 (first 600 elements): 7407.41 requests per second
MSET (10 keys): 45454.55 requests per second
- Redis分区
分区是将数据拆分为多个Redis实例的过程,因此每个实例只包含一部分键。
分区的优点
它允许更大的数据库,使用更多计算机的内存总和。如果没有分区,则限制为单个计算机可以支持的内存量。
它允许将计算能力扩展到多个核心和多个计算机,并将网络带宽扩展到多个计算机和网络适配器。
分区的缺点
通常不支持涉及多个键的操作。 例如,如果两个集合存储在映射到不同Redis实例的键中,则不能执行两个集合之间的交集操作。
不能使用涉及多个键的Redis事务。
分区粒度是关键,因此不可能使用单个巨大的键(如非常大的排序集合)来分割数据集。
使用分区时,数据处理更复杂。 例如,必须处理多个RDB/AOF文件,并获得数据的备份,需要聚合来自多个实例和主机的持久性文件。
添加和删除容量可能很复杂。 例如,Redis Cluster支持大多数透明的数据重新平衡,具有在运行时添加和删除节点的能力。但是,其他系统(如客户端分区和代理)不支持此功能。但可以使用一种叫作Presharding的技术来处理这方面的问题。
分区类型
Redis中有两种类型的分区。假设有四个Redis实例:R0,R1,R2,R3以许多代表用户的键,如user:1,user:2,…等等。
范围分区
范围分区通过将对象的范围映射到特定的Redis实例来实现。假设在上面示例中,从ID 0到ID 10000的用户将进入实例R0,而从ID 10001到ID 20000的用户将进入实例R1,以此类推。
哈希分区
在这种类型的分区中,使用散列函数(例如,模函数)将键转换成数字,然后将数据存储在不同的Redis实例中。
- 使用Redis有什么缺点
基本上使用redis都会碰到一些问题,常见的主要是四个问题
- 缓存和数据库双写一致性问题
首先要明白一个前提。就是如果对数据有强一致性要求,不能放缓存。我们所做的一切,只能保证最终一致性。另外,我们所做的方案其实从根本上来说,只能说降低不一致发生的概率,无法完全避免。因此,有强一致性要求的数据,不能放缓存。
具体做法是采取正确更新策略,先更新数据库,再删缓存。其次,因为可能存在删除缓存失败的问题,提供一个补偿措施即可,例如利用消息队列。
- 缓存雪崩问题
缓存雪崩,即缓存同一时间大面积的失效,这个时候又来了一波请求,结果请求都怼到数据库上,从而导致数据库连接异常。
解决方案:
给缓存的失效时间,加上一个随机值,避免集体失效。
使用互斥锁,但是该方案吞吐量明显下降了。
双缓存。我们有两个缓存,缓存A和缓存B。缓存A的失效时间为20分钟,缓存B不设失效时间。自己做缓存预热操作。然后细分以下几个小点:
从缓存A读数据库,有则直接返回。
A没有数据,直接从B读数据,直接返回,并且异步启动一个更新线程。
更新线程同时更新缓存A和缓存B。
- 缓存击穿问题
缓存击穿,即黑客故意去请求缓存中不存在的数据,导致每次请求都要去存储层去查询,这样缓存就失去了意义,所有的请求都集火到数据库上,从而造成数据库连接异常,类似DDOS。
解决方案:
利用互斥锁,缓存失效的时候,先去获得锁,得到锁了,再去请求数据库。没得到锁,则休眠一段时间重试。
采用异步更新策略,无论key是否取到值,都直接返回。value值中维护一个缓存失效时间,缓存如果过期,异步起一个线程去读数据库,更新缓存。需要做缓存预热(项目启动前,先加载缓存)操作。
提供一个能迅速判断请求是否有效的拦截机制,比如,利用布隆过滤器,内部维护一系列合法有效的key。迅速判断出,请求所携带的Key是否合法有效。如果不合法,则直接返回。
- 缓存的并发竞争问题
1). 如果对这个key操作,不要求顺序
这种情况下,准备一个分布式锁,大家去抢锁,抢到锁就做set操作即可,比较简单。
2). 如果对这个key操作,要求顺序
假设有一个key1,系统A需要将key1设置为valueA,系统B需要将key1设置为valueB,系统C需要将key1设置为valueC.期望按照key1的value值按照 valueA–>valueB–>valueC的顺序变化。这种时候我们在数据写入数据库的时候,需要保存一个时间戳。假设时间戳如下:
系统A key 1 {valueA 3:00}
系统B key 1 {valueB 3:05}
系统C key 1 {valueC 3:10}
那么,假设这会系统B先抢到锁,将key1设置为{valueB 3:05}。接下来系统A抢到锁,发现自己的valueA的时间戳早于缓存中的时间戳,那就不做set操作了。以此类推。
其他方法:比如利用队列,将set方法变成串行访问也可以。
- 单线程的redis为什么这么快
-
纯内存操作
-
单线程操作,避免了频繁的上下文切换
-
采用了非阻塞I/O多路复用机制
- redis的过期策略以及内存淘汰机制
redis采用的是定期删除+惰性删除策略。
为什么不用定时删除策略?
定时删除,用一个定时器来负责监视key,过期则自动删除。虽然内存及时释放,但是十分消耗CPU资源。在大并发请求下,CPU要将时间应用在处理请求,而不是删除key,因此没有采用这一策略.
定期删除+惰性删除是如何工作的呢?
定期删除,redis默认每个100ms检查,是否有过期的key,有过期key则删除。需要说明的是,redis不是每个100ms将所有的key检查一次,而是随机抽取进行检查(如果每隔100ms,全部key进行检查,redis岂不是卡死)。因此,如果只采用定期删除策略,会导致很多key到时间没有删除。
于是,惰性删除派上用场。也就是说在你获取某个key的时候,redis会检查一下,这个key如果设置了过期时间那么是否过期了?如果过期了此时就会删除。
采用定期删除+惰性删除就没其他问题了么?不是的,如果定期删除没删除key。然后你也没即时去请求key,也就是说惰性删除也没生效。这样,redis的内存会越来越高。那么就应该采用内存淘汰机制。在redis.conf中有一行配置
# maxmemory-policy volatile-lru
该配置就是配内存淘汰策略的,有如下选项:
-
noeviction:当内存不足以容纳新写入数据时,新写入操作会报错。应该没人用吧。
-
allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key。推荐使用,目前项目在用这种。
- allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个key。应该也没人用吧,你不删最少使用Key,去随机删。
-
volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key。这种情况一般是把redis既当缓存,又做持久化存储的时候才用。不推荐
-
volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key。依然不推荐
- volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除。不推荐
注意:如果没有设置 expire 的key, 不满足先决条件(prerequisites); 那么 volatile-lru, volatile-random 和 volatile-ttl 策略的行为, 和 noeviction(不删除) 基本上一致。
Redis与Memcached的区别与比较
-
Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,zset,hash等数据结构的存储。memcache支持简单的数据类型,String。
-
Redis支持数据的备份,即master-slave模式的数据备份。
-
Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用,而Memecache把数据全部存在内存之中
-
redis的速度比memcached快很多
-
Memcached是多线程,非阻塞IO复用的网络模型;Redis使用单线程的IO复用模型。
python 操作redis
redis提供两个类Redis和StrictRedis用于实现Redis的命令,StrictRedis用于实现大部分官方的命令,并使用官方的语法和命令,Redis是StrictRedis的子类,用于向后兼容旧版本的redis-py。
redis连接实例是线程安全的,可以直接将redis连接实例设置为一个全局变量,直接使用。如果需要另一个Redis实例(or Redis数据库)时,就需要重新创建redis连接实例来获取一个新的连接。同理,python的redis没有实现select命令。
redis-py使用connection pool来管理对一个redis server的所有连接,避免每次建立、释放连接的开销。默认,每个Redis实例都会维护一个自己的连接池。可以直接建立一个连接池,然后作为参数Redis,这样就可以实现多个Redis实例共享一个连接池
连接数据库
- StrictRedis
from redis import StrictRedis
# 使用默认方式连接到数据库
redis = StrictRedis(host='localhost', port=6379, db=0)
# 使用url方式连接到数据库
redis = StrictRedis.from_url('redis://@localhost:6379/1')
- ConnectionPool
from redis import StrictRedis,ConnectionPool
# 使用默认方式连接到数据库
pool = ConnectionPool(host='localhost', port=6379, db=0)
redis = StrictRedis(connection_pool=pool)
# 使用url方式连接到数据库
pool = ConnectionPool.from_url('redis://@localhost:6379/1')
redis = StrictRedis(connection_pool=pool)
- 构造url方式连接到数据库,有以下三种模式:
redis://[:password]@host:port/db # TCP连接
rediss://[:password]@host:port/db # Redis TCP+SSL 连接
unix://[:password]@/path/to/socket.sock?db=db # Redis Unix Socket 连接
- 导入和导出
redis-load
将数据导入到数据库中
redis-load -h # 获取帮助信息
< redis_data.json redis-load -u redis://@localhost:6379 # 将json数据导入数据库中
redis-dump
将数据库信息导出
redis-dump -h # 获取帮助信息
redis-dump -u redis://@localhost:6379 -d 1 > ./redis.data.jl # 导出到json文件
redis-dump -u redis://@localhost:6379 -f adsl:* > ./redis.data.jl # 导出adsl开头的数据
基本使用示例
#! /usr/bin/env python
#coding=utf-8
import redis
print redis.__file__
# 连接,可选不同数据库
r = redis.Redis(host='127.0.0.1', port=6379, db=1)
# -------------------------------------------
# 看信息
info = r.info()
for key in info:
print "%s: %s" % (key, info[key])
# 查数据库大小
print '\ndbsize: %s' % r.dbsize()
# 看连接
print "ping %s" % r.ping()
# 选数据库
#r.select(2)
# 移动数据去2数据库
#r.move('a',2)
# 其他
#r.save('a') # 存数据
#r.lastsave('a') # 取最后一次save时间
#r.flush() #刷新
#r.shutdown() #关闭所有客户端,停掉所有服务,退出服务器
#
#--------------------------------------------
# string(key,value)、hash、list、set、zset
# 不知道用的哪种类型?
# print r.get_type('a')
# -------------------------------------------
# string操作
print '-'*20
# 塞数据
r['c1'] = 'bar'
#或者
r.set('c2','bar')
#getset属性如果为True 可以在存新数据时将上次存储内容读出来
print 'getset:',r.getset('c2','jj')
#如果想设置一个递增的整数 每执行一次它自加1:
print 'incr:',r.incr('a')
#如果想设置一个递减的整数 please:
print 'decr:',r.decr('a')
# 取数据
print 'r['']:',r['c1']
#或者
print 'get:',r.get('a')
#或者 同时取一批
print 'mget:',r.mget('c1','c2')
#或者 同时取一批名字(key)很像的数据时不需要输入全部key
print 'keys:',r.keys('c*')
#又或者只想随机取一个:
print 'randomkey:',r.randomkey()
# 查看一个数据有没有 有 1 无0
print 'existes:',r.exists('a')
# 删数据 1是删除成功 0和None是没这个东西
print 'delete:',r.delete('cc')
# 支持批量操作的
print 'delete:',r.delete('c1','c2')
# 其他
r.rename('a','c3') #改名
r.expire('c3',10) #让数据10秒后过期
r.ttl('c3') #看剩余过期时间 不存在返回-1
#--------------------------------
# 序列(list)操作
print '-'*20
# 它是两头通的
# 塞入
r.push('b','gg')
r.push('b','hh')
# head 属性控制是不是从另一头塞
r.push('b','ee',head=True)
# 看长度
print 'list len:',r.llen('b')
# 取出一批数据
print 'list lrange:',r.lrange('b',start=0,end=-1)
# 取出一位
print 'list index 0:',r.lindex('b',0)
# 修剪列表
#若start 大于end,则将这个list清空
print 'list ltrim :',r.ltrim('b',start=0,end=3) #只留 从0到3四位
#--------------------------------
# 集合(set)操作
# 塞数据
r.sadd('s', 'a')
# 判断一个set长度为多少 不存在为0
r.scard('s')
# 判断set中一个对象是否存在
r.sismember('s','a')
# 求交集
r.sadd('s2','a')
r.sinter('s1','s2')
#求交集并将结果赋值
r.sinterstore('s3','s1','s2')
# 看一个set对象
r.smembers('s3')
# 求并集
r.sunion('s1','s2')
#求并集 并将结果返回
r.sunionstore('ss','s1','s2','s3')
# 求不同
# 在s1中有,但在s2和s3中都没有的数
r.sdiff('s1','s2','s3')
r.sdiffstore('s4','s1','s2')#
# 取个随机数
r.srandmember('s1')
#-------------------------------------
#zset 有序set
#'zadd', 'zcard', 'zincr', 'zrange', 'zrangebyscore', 'zrem', 'zscore'
# 分别对应
#添加, 数量, 自加1,取数据,按照积分(范围)取数据,删除,取积分
r.zadd('zset','mysql',1)
r.zadd('zset','redis',2)
print(r.zrange('zset',0,3))
print('获取字符串长度',r.zcard('zset'))
print('获取类型',r.type('zset'))
参考
版权声明:本文为博主原创文章,转载请注明出处。 旭日酒馆