为什么需要函数式编程
编程范式
编程语言主要有三种范式:
-
命令式编程(Imperative Programming): 专注于”如何去做”,这样不管”做什么”,都会按照你的命令去做。解决某一问题的具体算法实现。
-
函数式编程(Functional Programming):把运算过程尽量写成一系列嵌套的函数调用。
-
逻辑式编程(Logical Programming):它设定答案须符合的规则来解决问题,而非设定步骤来解决问题。过程是事实+规则=结果。
函数式编程(Functional Programming,FP),又称泛函编程,是一种编程范式,它将电脑运算视为数学上的函数计算,并且避免使用程序状态以及易变对象。函数编程语言最重要的基础是λ演算(lambda calculus)。而且λ演算的函数可以接受函数当作输入(引数)和输出(传出值)。
而在面向对象编程中,面向对象程序设计(英语:Object-oriented programming,缩写:OOP)是种具有对象概念的程序编程范型,同时也是一种程序开发的方法。它可能包含数据、属性、代码与方法。对象则指的是类的实例。它将对象作为程序的基本单元,将程序和数据封装其中,以提高软件的重用性、灵活性和扩展性,对象里的程序可以访问及经常修改对象相关连的数据。在面向对象程序编程里,计算机程序会被设计成彼此相关的对象。
对象与对象之间的关系是面向对象编程首要考虑的问题,而在函数式编程中,所有的数据都是不可变的,不同的函数之间通过数据流来交换信息,函数作为FP中的一等公民,享有跟数据一样的地位,可以作为参数传递给下一个函数,同时也可以作为返回值。
面向对象编程的优点
面向对象程序设计可以看作一种在程序中包含各种独立而又互相调用的对象的思想,这与传统的思想刚好相反。传统的程序设计主张将程序看作一系列函数的集合,或者直接就是一系列对电脑下达的指令。面向对象程序设计中的每一个对象都应该能够接受数据、处理数据并将数据传达给其它对象,因此它们都可以被看作一个小型的“机器”,即对象。目前已经被证实的是,面向对象程序设计推广了程序的灵活性和可维护性,并且在大型项目设计中广为应用。此外,支持者声称面向对象程序设计要比以往的做法更加便于学习,因为它能够让人们更简单地设计并维护程序,使得程序更加便于分析、设计、理解。同时它也是易拓展的,由于继承、封装、多态的特性,自然设计出高内聚、低耦合的系统结构,使得系统更灵活、更容易扩展,而且成本较低。
在面向对象编程的基础上发展出来的23种设计模式广泛应用于现今的软件工程中,极大方便了代码的书写与维护。
-
创建型模式,共五种:工厂方法模式、抽象工厂模式、单例模式、建造者模式、原型模式。
-
结构型模式,共七种:适配器模式、装饰器模式、代理模式、外观模式、桥接模式、组合模式、享元模式。
-
行为型模式,共十一种:策略模式、模板方法模式、观察者模式、迭代子模式、责任链模式、命令模式、备忘录模式、状态模式、访问者模式、中介者模式、解释器模式。
面向对象编程的缺点
面向对象编程以数据为核心,所以在多线程并发编程中,多个线程同时操作数据的时候可能会导致数据修改的不确定性。
在现在的软件工程中,由于面向对象编程的滥用,导致了很多问题。首先就是为了写可重用的代码而产生了很多无用的代码,导致代码膨胀,同时很多人并没有完全理解面向对象思想,为了面向对象而面向对象,使得最终的代码晦涩难懂,给后期的维护带来了很大的问题。所以对于大项目的开发,使用面向对象会出现一些不适应的情况。
面向对象虽然开发效率高但是代码的运行效率比起面向过程要低很多,这也限制了面向对象的使用场景不能包括那些对性能要求很苛刻的地方。
函数式编程的本质
函数式编程中的函数这个术语不是指计算机中的函数(实际上是Subroutine),而是指数学中的函数,即自变量的映射。也就是说一个函数的值仅决定于函数参数的值,不依赖其他状态。比如sqrt(x)函数计算x的平方根,只要x不变,不论什么时候调用,调用几次,值都是不变的。
在函数式语言中,函数作为一等公民(first class),可以在任何地方定义,在函数内或函数外,可以作为函数的参数和返回值,可以对函数进行组合。所谓“第一等公民”,是指函数和其他数据类型拥有平等的地位,可以赋值给变量,也可以作为参数传入另一个函数,或者作为别的函数的返回值。 当编程语言将函数视作“第一等公民”,那么相当于它支持了高阶函数,因为高阶函数就是至少满足下列一个条件的函数
-
接受一个或多个函数作为输入
-
输出一个函数
纯函数式编程语言中的变量也不是命令式编程语言中的变量,即存储状态的单元,而是代数中的变量,即一个值的名称。变量的值是不可变的(immutable),也就是说不允许像命令式编程语言中那样多次给一个变量赋值。比如说在命令式编程语言我们写“x = x + 1”,这依赖可变状态的事实,拿给程序员看说是对的,但拿给数学家看,却被认为这个等式为假。
函数式语言的如条件语句,循环语句也不是命令式编程语言中的控制语句,而是函数的语法糖,比如在Scala语言中,if else不是语句而是三元运算符,是有返回值的。
严格意义上的函数式编程意味着不使用可变的变量,赋值,循环和其他命令式控制结构进行编程。
从理论上说,函数式语言也不是通过冯诺伊曼体系结构的机器上运行的,而是通过λ演算来运行的,就是通过变量替换的方式进行,变量替换为其值或表达式,函数也替换为其表达式,并根据运算符进行计算。λ演算是图灵完全(Turing completeness)的,但是大多数情况,函数式程序还是被编译成(冯诺依曼机的)机器语言的指令执行的。
函数式编程的优点
在函数式编程中,由于数据全部都是不可变的,所以没有并发编程的问题,是多线程安全的。可以有效降低程序运行中所产生的副作用,对于快速迭代的项目来说,函数式编程可以实现函数与函数之间的热切换而不用担心数据的问题,因为它是以函数作为最小单位的,只要函数与函数之间的关系正确即可保证结果的正确性。
函数式编程的表达方式更加符合人类日常生活中的语法,代码可读性更强。实现同样的功能函数式编程所需要的代码比面向对象编程要少很多,代码更加简洁明晰。函数式编程广泛运用于科学研究中,因为在科研中对于代码的工程化要求比较低,写起来更加简单,所以使用函数式编程开发的速度比用面向对象要高很多,如果是对开发速度要求较高但是对运行资源要求较低同时对速度要求较低的场景下使用函数式会更加高效。
函数式编程的缺点
由于所有的数据都是不可变的,所以所有的变量在程序运行期间都是一直存在的,非常占用运行资源。同时由于函数式的先天性设计导致性能一直不够。虽然现代的函数式编程语言使用了很多技巧比如惰性计算等来优化运行速度,但是始终无法与面向对象的程序相比,当然面向对象程序的速度也不够快。
函数式编程虽然已经诞生了很多年,但是至今为止在工程上想要大规模使用函数式编程仍然有很多待解决的问题,尤其是对于规模比较大的工程而言。如果对函数式编程的理解不够深刻就会导致跟面相对象一样晦涩难懂的局面。
总的来说函数式编程和面向对象编程各有利弊,一个语法更加自由,一个健壮性更好。作为程序员应该对两种编程方式都有所了解,不管是哪种方式,只要能够很好的解决当前的问题就是正确的方式,毕竟对于软件工程来说解决问题是最主要的,用的工具反而没有那么重要,就像对程序员来说语言不重要,重要的是解决问题的思想。
函数式编程的特性
-
易于理解,抽象度高
-
高阶函数(Higher-order function)
高阶函数就是参数为函数或返回值为函数的函数。现象上就是函数传进传出,有了高阶函数,就可以将复用的粒度降低到函数级别,相对于面向对象语言,复用的粒度更低。高阶函数具有以下特点:
-
变量可以指向函数
-
函数的参数可以接收变量
-
一个函数可以接收另一个函数作为参数
高阶函数提供了一种函数级别上的依赖注入(或反转控制)机制,很多GoF设计模式都可以用高阶函数来实现,如Visitor,Strategy,Decorator等。比如Visitor模式就可以用集合类的map()或foreach()高阶函数来替代。
- 柯里化(Currying ,局部调用Partial application)
是把接受多个参数的函数变换成接受一个单一参数(最初函数的第一个参数)的函数,并且返回接受余下的参数而且返回结果的新函数的技术。
当一个函数没有传入全部所需参数时,它会返回另一个函数(这个返回的函数会记录那些已经传入的参数),这种情况叫作柯里化。 在直觉上,柯里化声称“如果你固定某些参数,你将得到接受余下参数的一个函数”。currying完成的事情就是函数(接口)封装,它将一个已有的函数(接口)做封装,得到一个新的函数(接口),这与适配器模式(Adapter pattern)的思想是一致的。
为什么要柯里化:
-
延迟计算。
-
参数复用。当在多次调用同一个函数,并且传递的参数绝大多数是相同的,那么该函数可能是一个很好的柯里化候选。
-
动态创建函数。这可以是在部分计算出结果后,在此基础上动态生成新的函数处理后面的业务,这样省略了重复计算。或者可以通过将要传入调用函数的参数子集,部分应用到函数中,从而动态创造出一个新函数,这个新函数保存了重复传入的参数(以后不必每次都传)。
- 引用透明(Referential transparency)
函数式编程只是返回新的值,不修改系统变量。因此,不修改变量,也是它的一个重要特点。在其他类型的语言中,变量往往用来保存”状态”(state)。不修改变量,意味着状态不能保存在变量中。函数式编程使用参数保存状态,最好的例子就是递归。同样由于变量不可变,纯函数编程语言无法实现循环,这是因为For循环使用可变的状态作为计数器,而While循环或DoWhile循环需要可变的状态作为跳出循环的条件。因此在函数式语言里就只能使用递归来解决迭代问题,这使得函数式编程严重依赖递归。
引用透明(Referential transparency),指的是函数的运行不依赖于外部变量或”状态”,只依赖于输入的参数,任何时候只要参数相同,引用函数所得到的返回值总是相同的。其他类型的语言,函数的返回值往往与系统状态有关,不同的状态之下,返回值是不一样的。这就叫”引用不透明”,很不利于观察和理解程序的行为。没有可变的状态,函数就是引用透明(Referential transparency)
- 没有副作用(No Side Effect)。
副作用(side effect),指的是函数内部与外部互动(最典型的情况,就是修改全局变量的值),产生运算以外的其他结果。函数式编程强调没有”副作用”,意味着函数要保持独立,所有功能就是返回一个新的值,没有其他行为,尤其是不得修改外部变量的值。函数即不依赖外部的状态也不修改外部的状态,函数调用的结果不依赖调用的时间和位置,这样写的代码容易进行推理,不容易出错。这使得单元测试和调试都更容易。还有一个好处是,由于函数式语言是面向数学的抽象,更接近人的语言,而不是机器语言,代码会比较简洁,也更容易被理解。
- 可移植性/自文档化(Portable / Self-Documenting)
由于不依赖于函数外的变量,因此可移植性好;纯函数是完全自给自足的,它需要的所有东西都能轻易获得。
- 无锁并发
没有副作用使得函数式编程各个独立的部分的执行顺序可以随意打乱,(多个线程之间)不共享状态,不会造成资源争用(Race condition),也就不需要用锁来保护可变状态,也就不会出现死锁,这样可以更好地进行无锁(lock-free)的并发操作。尤其是在对称多处理器(SMP)架构下能够更好地利用多个处理器(核)提供的并行处理能力。
- 惰性求值(Lazy evaluation,也称作call-by-need)
惰性求值(lazy evaluation,也称作call-by-need)是在将表达式赋值给变量(或称作绑定)时并不计算表达式的值,而在变量第一次被使用时才进行计算。这样就可以通过避免不必要的求值提升性能。
- 代码简洁,开发快速
函数式编程大量使用函数,减少了代码的重复,因此程序比较短,开发速度较快。
- 复用粒度最小
函数式的利用粒度更小,以函数为单位。
- 接近自然语言,易于理解
函数式编程的自由度很高,可以写出很接近自然语言的代码。
- 易于测试,不容易出错
程序中的状态不好维护,在并发的时候更不好维护。函数即不依赖外部的状态也不修改外部的状态,函数调用的结果不依赖调用的时间和位置,这样写的代码容易进行推理,不容易出错。这使得单元测试和调试都更容易。
- 易于”并发编程”
函数式编程不需要考虑”死锁”(deadlock),因为它不修改变量,所以根本不存在”锁”线程的问题。不必担心一个线程的数据,被另一个线程修改,所以可以很放心地把工作分摊到多个线程,部署”并发编程”(concurrency)。
- 代码的热升级
函数式编程没有副作用,只要保证接口不变,内部实现是外部无关的。所以,可以在运行状态下直接升级代码,不需要重启,也不需要停机。
- 语法糖
指程序的可阅读性更高、可以给我们带来方便,更简洁的写法,提高开发编码效率。
某种语言中添加了某种语法,这种语法对功能没有影响,但可以提高可阅读性、间接性等,则称这种语法为该语言的语法糖
- 不擅长处理可变状态和IO
处理可变状态和处理IO,要么引入可变变量,要么通过Monad来进行封装(如State Monad和IO Monad)。
Python函数式编程
Python作为一门脚本语言,也具有一些函数式编程的思想,主要体现在下面几个方面:
-
Python的一些语法,比如lambda、列表解析、字典解析、生成器、iter等
-
Python的一些内置函数,包括map、reduce、filter、all、any、enumerate、zip等
-
Python的一些内置模块,比如 itertools、functools 和 operator模块等
-
Python的一些第三方库,比如fn.py, toolz等
python部分支持函数式编程,具有如下特点:
-
不是纯函数式编码:允许有变量
-
支持高阶函数:函数也可以作为变量传入
-
支持闭包:有了闭包就能返回函数
-
有限度地支持匿名函数
函数式编程也有自己的关键字。在Python语言中,用于函数式编程的主要由3个基本函数和1个算子,仅仅采用这几个函数和算子就基本上可以实现任意Python程序。
-
基本函数:map()、reduce()、filter()
-
算子(operator):lambda
map
map()函数接收两个参数,一个是函数,一个是Iterable,map将传入的函数依次作用到序列的每个元素,并把结果作为新的Iterator返回。例如,对于list [1, 2, 3, 4, 5, 6, 7, 8, 9],如果希望把list的每个元素都作平方,就可以用map()函数:
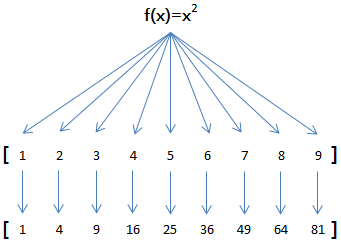
因此,我们只需要传入函数f(x)=x*x,就可以利用map()函数完成这个计算:
def f(x):
return x*x
print(list(map(f, [1, 2, 3, 4, 5, 6, 7, 8, 9])))
result:
[1, 4, 9, 16, 25, 36, 49, 64, 81]
map()函数不改变原有的 list,而是返回一个新的 list。利用map()函数,可以把一个 list 转换为另一个 list,只需要传入转换函数。由于list包含的元素可以是任何类型,因此,map() 不仅仅可以处理只包含数值的 list,事实上它可以处理包含任意类型的 list,只要传入的函数f可以处理这种数据类型。
由于map()返回的是map object,所以要转换为list后才能够print。
reduce
reduce()函数也是Python内置的一个高阶函数。reduce()函数接收的参数和 map()类似,一个函数 f,一个list,但行为和 map()不同,reduce()传入的函数 f 必须接收两个参数,reduce()对list的每个元素反复调用函数f,并返回最终结果值。
例如,编写一个f函数,接收x和y,返回x和y的和:
from functools import reduce
def f(x,y):
return x+y
print(reduce(f, [1, 2, 3, 4, 5, 6, 7, 8, 9]))
result:
45
调用 reduce(f, [1, 2, 3, 4, 5, 6, 7, 8, 9])时,reduce函数将做如下计算:
-
先计算头两个元素:f(1, 2),结果为3;
-
再把结果和第3个元素计算:f(3, 3),结果为6;
-
……..;
-
再把结果和第9个元素计算:f(36, 9),结果为45;
-
由于没有更多的元素了,计算结束,返回结果45。
上述计算实际上是对 list 的所有元素求和。虽然Python内置了求和函数sum(),但是,利用reduce()求和也很简单。
reduce()还可以接收第3个可选参数,作为计算的初始值。如果把初始值设为100,计算:
from functools import reduce
def f(x,y):
return x+y
print(reduce(f, [1, 2, 3, 4, 5, 6, 7, 8, 9],100))
结果将变为125,因为第一轮是计算初始值和第一个元素:f(100, 1),结果为101。
filter
和map()类似,filter()也接收一个函数和一个序列。和map()不同的是,filter()把传入的函数依次作用于每个元素,然后根据返回值是True还是False决定保留还是丢弃该元素。
def is_not_empty(s):
return s and len(s.strip()) > 0
print(list(filter(is_not_empty, ['test', None, '', 'str', ' ', 'END'])))
result:
['test', 'str', 'END']
lambda
当我们在传入函数时,有些时候,不需要显式地定义函数,直接传入匿名函数更方便。
在Python中,对匿名函数提供了有限支持。还是以map()函数为例,计算f(x)=x^2时,除了定义一个f(x)的函数外,还可以直接传入匿名函数:
>>> list(map(lambda x: x * x, [1, 2, 3, 4, 5, 6, 7, 8, 9]))
[1, 4, 9, 16, 25, 36, 49, 64, 81]
关键字lambda表示匿名函数,冒号前面的x表示函数参数。匿名函数有个限制,就是只能有一个表达式,不用写return,返回值就是该表达式的结果。用匿名函数有个好处:因为函数没有名字,不必担心函数名冲突。此外,匿名函数也是一个函数对象,也可以把匿名函数赋值给一个变量,再利用变量来调用该函数:
>>> f = lambda x: x * x
>>> f
<function <lambda> at 0x101c6ef28>
>>> f(5)
25
同样,也可以把匿名函数作为返回值返回,比如:
def build(x, y):
return lambda: x * x + y * y
Python对匿名函数的支持有限,只有一些简单的情况下可以使用匿名函数。
高阶函数
- 变量可以指向函数
以Python内置的求绝对值的函数abs()为例,调用该函数用以下代码:
# 调用abs()函数
In [1]: abs(-10)
Out[1]: 10
# 只写abs
In [3]: abs
Out[3]: <function abs>
依据如上例子,可见abs(-10)是对函数的调用,而只写abs是函数本身。要获得函数调用结果,我们可以把结果赋值给变量:
In [4]: x = abs(-10)
In [5]: x
Out[5]: 10
现在把函数本身赋值给变量:
In [6]: fun_abs = abs
In [8]: fun_abs
Out[8]: <function abs>
可见函数本身也可以赋值给变量,即:变量可以指向函数。上例中变量fun_abs已经指向abs函数本身,调用方法完全和abs一样:
In [9]: fun_abs(-10)
Out[9]: 10
- 传入函数
既然变量可以指向函数,函数的参数能接收变量,那么一个函数就可以接收另一个函数作为参数,这种函数就称之为高阶函数。
一个最简单的高阶函数:
In [10]: def add(x, y, f):
....: return f(x) + f(y)
....:
In [11]: add(-5, -6, abs)
Out[11]: 11
我们将变量x,y和函数abs作为参数传给add()。在add里调用了f的功能。 整个行为流有些像这样:
x = -5
y = -6
f = abs
f(x) + f(y) ==> abs(-5) + abs(6) ==> 11
return 11
把函数作为参数传入,这样的函数称为高阶函数,函数式编程就是指这种高度抽象的编程范式。
- 返回函数
高阶函数除了可以接受函数作为参数外,还可以把函数作为结果值返回。
我们来实现一个可变参数的求和。通常情况下,求和的函数是这样定义的:
def sum(*args):
ax = 0
for n in args:
ax = ax + n
return ax
但是,如果不需要立刻求和,而是在后面的代码中,根据需要再计算怎么办?可以不返回求和的结果,而是返回求和的函数:
def lazy_sum(*args):
def sum():
ax = 0
for n in args:
ax = ax + n
return ax
return sum
f = lazy_sum(1, 3, 5, 7, 9)
print(f)
当我们调用lazy_sum()时,返回的并不是求和结果,而是求和函数:
<function lazy_sum.<locals>.sum at 0x0000000008E6AF28>
调用函数f时,才真正计算求和的结果:
>>> f()
25
在这个例子中,我们在函数lazy_sum中又定义了函数sum,并且,内部函数sum可以引用外部函数lazy_sum的参数和局部变量,当lazy_sum返回函数sum时,相关参数和变量都保存在返回的函数中,这种称为“闭包(Closure)”的程序结构拥有极大的威力。
当我们调用lazy_sum()时,每次调用都会返回一个新的函数,即使传入相同的参数,f1()和f2()的调用结果互不影响:
>>> f1 = lazy_sum(1, 3, 5, 7, 9)
>>> f2 = lazy_sum(1, 3, 5, 7, 9)
>>> f1==f2
False
闭包
闭包是由函数及其相关的引用环境组合而成的实体(即:闭包=函数+引用环境)
内层函数引用了外层函数的变量(参数也算变量),然后返回内层函数的情况,称为闭包(Closure)。特点是返回的函数还引用了外层函数的局部变量,所以,要正确使用闭包,就要确保引用的局部变量在函数返回后不能变。
python中的闭包从表现形式上定义(解释)为:如果在一个内部函数里,对在外部作用域(但不是在全局作用域)的变量进行引用,那么内部函数就被认为是闭包(closure).
def ExFunc(n):
sum=n
def InsFunc():
return sum+1
return InsFunc
myFunc=ExFunc(10)
print(myFunc()) #11
myFunc=ExFunc(20)
print(myFunc()) #21
在这段程序中,函数InsFunc是函数ExFunc的内嵌函数,并且是ExFunc函数的返回值。我们注意到一个问题:内嵌函数InsFunc中 引用到外层函数中的局部变量sum,所以InsFunc()是一个闭包。
当我们调用分别由不同的参数调用 ExFunc函数得到的函数时(myFunc(),myAnotherFunc()),得到的结果是隔离的,也就是说每次调用ExFunc函数后都将生成并保存一个新的局部变量sum。其实这里ExFunc函数返回的就是闭包。
- 引用环境
按照命令式语言的规则,ExFunc函数只是返回了内嵌函数InsFunc的地址,在执行InsFunc函数时将会由于在其作用域内找不到sum变量而出 错。而在函数式语言中,当内嵌函数体内引用到体外的变量时,将会把定义时涉及到的引用环境和函数体打包成一个整体(闭包)返回。现在给出引用环境的定义就 容易理解了:引用环境是指在程序执行中的某个点所有处于活跃状态的约束(一个变量的名字和其所代表的对象之间的联系)所组成的集合。闭包的使用和正常的函 数调用没有区别。
由于闭包把函数和运行时的引用环境打包成为一个新的整体,所以就解决了函数编程中的嵌套所引发的问题。如上述代码段中,当每次调用ExFunc函数 时都将返回一个新的闭包实例,这些实例之间是隔离的,分别包含调用时不同的引用环境现场。不同于函数,闭包在运行时可以有多个实例,不同的引用环境和相同的函数组合可以产生不同的实例。
def count():
fs = []
for i in range(1, 4):
def f():
return i*i
fs.append(f)
return fs
f1, f2, f3 = count()
print(f1(),f2(),f3())
根据代码判断,调用f1(),f2()和f3()结果应该是11=1,22=4,33=9,但是对不对呢,实际结果全部都是 9。原因就是当把函数加入flist列表里时,python还没有给i赋值,只有当执行时,再去找i的值是什么。当count()函数返回了3个函数时,这3个函数所引用的变量 i 的值已经变成了3。由于f1、f2、f3并没有被调用,所以,此时他们并未计算 ii。
因此,返回函数不要引用任何循环变量,或者后续会发生变化的变量。要实现预期的效果,需要修改函数定义,在定义时指定参数。
def count():
fs = []
for i in range(1, 4):
def f(x=i):
return x*x
fs.append(f)
return fs
f1, f2, f3 = count()
print(f1(),f2(),f3())
result:
1 4 9
- 使用闭包注意事项
- 闭包中是不能修改外部作用域的局部变量的
def foo():
m = 0
def foo1():
m = 1
print(m)
print (m)
foo1()
print (m)
foo()
result:
0
1
0
从执行结果可以看出,虽然在闭包里面也定义了一个变量m,但是其不会改变外部函数中的局部变量m。
- 修改外部变量
def foo():
a = 1
def bar():
a = a + 1
return a
return bar
c = foo()
print(c())
result:
line 9, in <module>
print(c())
line 4, in bar
a = a + 1
UnboundLocalError: local variable 'a' referenced before assignment
这是因为在执行代码 c = foo()时,python会导入全部的闭包函数体bar()来分析其的局部变量,python规则指定所有在赋值语句左面的变量都是局部变量,则在闭包bar()中,变量a在赋值符号”=”的左面,被python认为是bar()中的局部变量。再接下来执行print c()时,程序运行至a = a + 1时,因为先前已经把a归为bar()中的局部变量,所以python会在bar()中去找在赋值语句右面的a的值,结果找不到,就会报错。
要修改外部变量,有两种方法:
def foo():
a = 1
def bar():
# 方法1 nonlocal关键字声明
nonlocal a
a = a + 1 #方法2 修改变量为容器:a[0] = a[0] + 1 return a[0]
return a
return bar
c = foo()
print(c())
- 用途1:当闭包执行完后,仍然能够保持住当前的运行环境。
如果希望函数的每次执行结果,都是基于这个函数上次的运行结果。我以一个类似棋盘游戏的例子来说明。假设棋盘大小为50*50,左上角为坐标系原点(0,0),我需要一个函数,接收2个参数,分别为方向(direction),步长(step),该函数控制棋子的运动。棋子运动的新的坐标除了依赖于方向和步长以外,当然还要根据原来所处的坐标点,用闭包引用环境的特点就可以保持住这个棋子原来所处的坐标。
origin = [0, 0] # 坐标系统原点
legal_x = [0, 50] # x轴方向的合法坐标
legal_y = [0, 50] # y轴方向的合法坐标
def create(pos=origin):
def player(direction,step):
# 这里应该首先判断参数direction,step的合法性,比如direction不能斜着走,step不能为负等
# 然后还要对新生成的x,y坐标的合法性进行判断处理,这里主要是想介绍闭包,就不详细写了。
new_x = pos[0] + direction[0]*step
new_y = pos[1] + direction[1]*step
pos[0] = new_x
pos[1] = new_y
#注意!此处不能写成 pos = [new_x, new_y],原因在上文有说过
return pos
return player
player = create() # 创建棋子player,起点为原点
print (player([1,0],10)) # 向x轴正方向移动10步
print (player([0,1],20)) # 向y轴正方向移动20步
print (player([-1,0],10)) # 向x轴负方向移动10步
result:
[10, 0]
[10, 20]
[0, 20]
- 用途2,闭包可以根据外部作用域的局部变量来得到不同的结果
可以修改外部的变量,闭包根据这个变量展现出不同的功能。比如有时我们需要对某些文件的特殊行进行分析,先要提取出这些特殊行。
def make_filter(keep):
def the_filter(file_name):
file = open(file_name)
lines = file.readlines()
file.close()
filter_doc = [i for i in lines if keep in i]
return filter_doc
return the_filter
filter = make_filter("pass")
filter_result = filter("result.txt")
装饰器
由于函数也是一个对象,而且函数对象可以被赋值给变量,所以,通过变量也能调用该函数。
def now():
print('2018-12-4')
f = now
f()
函数对象有一个__name__属性,可以拿到函数的名字:
>>> now.__name__
'now'
>>> f.__name__
'now'
假设我们要增强now()函数的功能,比如,在函数调用前后自动打印日志,但又不希望修改now()函数的定义,这种在代码运行期间动态增加功能的方式,称之为“装饰器”(Decorator)。本质上,decorator就是一个返回函数的高阶函数。所以,我们要定义一个能打印日志的decorator,可以定义如下:
def log(func):
def wrapper(*args, **kw):
print('call %s():' % func.__name__)
return func(*args, **kw)
return wrapper
观察上面的log,因为它是一个decorator,所以接受一个函数作为参数,并返回一个函数。我们要借助Python的@语法,把decorator置于函数的定义处:
@log
def now():
print('2018-12-4')
调用now()函数,不仅会运行now()函数本身,还会在运行now()函数前打印一行日志:
>>> now()
call now():
2018-12-4
把@log放到now()函数的定义处,相当于执行了语句:
now = log(now)
由于log()是一个decorator,返回一个函数,所以,原来的now()函数仍然存在,只是现在同名的now变量指向了新的函数,于是调用now()将执行新函数,即在log()函数中返回的wrapper()函数。wrapper()函数的参数定义是(*args, **kw),因此,wrapper()函数可以接受任意参数的调用。在wrapper()函数内,首先打印日志,再紧接着调用原始函数。如果decorator本身需要传入参数,那就需要编写一个返回decorator的高阶函数,写出来会更复杂。比如,要自定义log的文本:
def log(text):
def decorator(func):
def wrapper(*args, **kw):
print('%s %s():' % (text, func.__name__))
return func(*args, **kw)
return wrapper
return decorator
这个3层嵌套的decorator用法如下:
@log('execute')
def now():
print('2018-12-4')
偏函数
Python的functools模块提供了很多有用的功能,其中一个就是偏函数(Partial function)。要注意的是这里的偏函数和数学意义上的偏函数不一样。
通过设定参数的默认值,可以降低函数调用的难度。而偏函数也可以做到这一点。举例如下:
int()函数可以把字符串转换为整数,当仅传入字符串时,int()函数默认按十进制转换:
>>> int('12345')
12345
但int()函数还提供额外的base参数,默认值为10。如果传入base参数,就可以做N进制的转换:
>>> int('12345', base=8)
5349
>>> int('12345', 16)
74565
假设要转换大量的二进制字符串,每次都传入int(x, base=2)非常麻烦,于是,我们想到,可以定义一个int2()的函数,默认把base=2传进去:
def int2(x, base=2):
return int(x, base)
这样,我们转换二进制就非常方便了:
>>> int2('1000000')
64
>>> int2('1010101')
85
functools.partial就是帮助我们创建一个偏函数的,不需要我们自己定义int2(),可以直接使用下面的代码创建一个新的函数int2:
>>> import functools
>>> int2 = functools.partial(int, base=2)
>>> int2('1000000')
64
>>> int2('1010101')
85
所以,简单总结functools.partial的作用就是,把一个函数的某些参数给固定住(也就是设置默认值),返回一个新的函数,调用这个新函数会更简单。
注意到上面的新的int2函数,仅仅是把base参数重新设定默认值为2,但也可以在函数调用时传入其他值:
>>> int2('1000000', base=10)
1000000
最后,创建偏函数时,实际上可以接收函数对象、*args和**kw这3个参数,当传入:
int2 = functools.partial(int, base=2)
实际上固定了int()函数的关键字参数base,也就是:
int2('10010')
相当于:
kw = { 'base': 2 }
int('10010', **kw)
当函数的参数个数太多,需要简化时,使用functools.partial可以创建一个新的函数,这个新函数可以固定住原函数的部分参数,从而在调用时更简单。
其他常用语法和函数
- 列表解析
将range(5)的每个元素进行平方:
a_list = [item**2 for item in range(5)]
print(a_list) # [0, 1, 4, 9, 16]
- 字典解析
将range(5)的每个元素进行平方并作为value,key为一个指示:
a_dict = {"%d^2" % item: item**2 for item in range(5)}
print(a_dict) # {'3^2': 9, '2^2': 4, '1^2': 1, '0^2': 0, '4^2': 16}
- 生成器
和列表解析比较类似,区别在于它的结果是generator object,不能直接打印,但可以进行迭代(使用next函数、放入for循环等)。
a_generator = (item**2 for item in range(5))
print(a_generator) # <generator object <genexpr> at 0x10e366570>
print(next(a_generator)) # 0
print(next(a_generator)) # 1
- iter函数和next函数
一个list类型不能使用next函数,需将其转化为iterator类型。
a_list_generator = iter(a_list)
print(next(a_list_generator)) # 0
print(type(a_list), type(a_list_generator)) # <class 'list'> <class 'list_iterator'>
- all、any函数
判定一个可迭代对象是否全为True或者有为True的:
print(all([0, 1, 2])) # False
print(any([0, 1, 2])) # True
- enumerate函数,如果想迭代一个列表或者元组,又想知道当前迭代元素的index值,那么:
for index, item in enumerate(range(5)):
print("%d: %d" % (index, item)) # 0: 0 \n 1: 1 \n 2: 2 ......
- zip函数,映射两个或多个可迭代对象,组成新的可迭代对象:
for a, b in zip([1, 2, 3], ["a", "b", "c"]):
print(a, b) # 1 a \n 2 b \n 3 c
a_dict = dict(zip([1, 2, 3], ["a", "b", "c"]))
print(a_dict) # {1: 'a', 2: 'b', 3: 'c'}
参考
版权声明:本文为博主原创文章,转载请注明出处。 旭日酒馆