概念
1.决策树(Decision Tree)
决策树(Decision Tree)是一种基本的分类与回归方法。
决策树模型呈树形结构,在分类问题中,表示基于特征对实例进行分类的过程。它可以认为是if-then规则的集合,也可以认为是定义在特征空间与类空间上的条件概率分布。相比朴素贝叶斯分类,决策树的优势在于构造过程不需要任何领域知识或参数设置,因此在实际应用中,对于探测式的知识发现,决策树更加适用。

一棵决策树可以分成三个部分:叶节点,非叶节点,分支。叶节点对应决策结果,也即分类任务中的类别标记;非叶节点(包括根节点)对应一个判定问题(某属性=?);分支对应父节点判定问题的不同答案(可能的属性值),可能连向一个非叶节点的子节点,也可能连向叶节点。
1 算法流程
决策树学习的目的是为了产生一棵泛化能力强,即处理未见示例能力强的决策树。
决策树生成是一个递归过程:
生成算法:
- 传入训练集和属性集
- 生成一个新节点
- 若此时数据集中所有样本都属于同一类,则把新节点设置为该类的叶节点,然后返回$^1$。
- 若此时属性集为空,或者数据集中所有样本在属性集余下的所有属性上取值都相同,无法进一步划分,则把新节点设置为叶节点,类标记为数据集中样本数最多的类,然后返回$^2$
- 从属性集中选择一个最优划分属性
- 为该属性的每个属性值生成一个分支,并按属性值划分出子数据集
- 若分支对应的子数据集为空,无法进一步划分,则直接把子节点设置为叶节点,类标记为父节点数据集中样本数最多的类,然后返回$^3$
- 将子数据集和去掉了划分属性的子属性集作为算法的传入参数,继续生成该分支的子决策树。
3处返回中的第2处和第3处设置叶节点的类标记原理有所不同。第2处将类标记设置为当前节点对应为数据集中样本数最多的类,这是利用当前节点的后验分布;第3处将类标记设置为为父节点数据集中样本数最多的类,这是把父节点的样本分布作为当前节点的先验分布。
淫的决策树学习的生成算法是ID3和C4.5,算法流程如下 :

 2 优点
2 优点
- 易于理解和实现,人们在在学习过程中不需要使用者了解很多的背景知识,这同时是它的能够直接体现数据的特点,只要通过解释后都有能力去理解决策树所表达的意义。
- 对于决策树,数据的准备往往是简单或者是不必要的,而且能够同时处理数据型和常规型属性,在相对短的时间内能够对大型数据源做出可行且效果良好的结果。
- 易于通过静态测试来对模型进行评测,可以测定模型可信度;如果给定一个观察的模型,那么根据所产生的决策树很容易推出相应的逻辑表达式。
- 简单易懂,原理清晰,决策树可以实现可视化
- 使用决策树的代价是数据点的对数级别
- 能够处理数值和分类数据
- 能够处理多路输出问题
- 使用白盒子模型(内部结构可以直接观测的模型)一个给定的情况是可以观测的,那么就可以用布尔逻辑解释这个结果。相反,如果在一个黑盒模型(ANN)结果可能很难解释
- 可以通过统计学检验验证模型。这也使得模型的可靠性计算变得可能
- 即使模型假设违反产生数据的真实模型,表现性能依旧很好
3 缺点
- 连续性的字段比较难预测。
- 有时间顺序的数据,需要很多预处理的工作。
- 类别太多时,错误可能就会增加的比较快。
- 般的算法分类的时候,只是根据一个字段来分类。
- 可能会建立过于复杂的规则,即过拟合。为避免这个问题,剪枝、设置叶节点的最小样本数量、设置决策树的最大深度有时候是必要的。
- 决策树有时候是不稳定的,因为数据微小的变动,可能生成完全不同的决策树。 可以通过总体平均(ensemble)减缓这个问题。应该指的是多次实验。
- 学习最优决策树是一个NP完全问题。所以,实际决策树学习算法是基于试探性算法,例如在每个节点实现局部最优值的贪心算法。这样的算法是无法保证返回一个全局最优的决策树。可以通过随机选择特征和样本训练多个决策树来缓解这个问题。
- 有些问题学习起来非常难,因为决策树很难表达。如:异或问题、奇偶校验或多路复用器问题
- 如果有些因素占据支配地位,决策树是有偏的。因此建议在拟合决策树之前先平衡数据的影响因子
2.优化目标
在决策树模型中,我们不断进行判定的初衷是希望划分后需要考虑的可能更少,准确地说,是希望所得子节点的纯度(purity)更高(也可以说是混乱程度更低)。
信息熵(information entropy)是一种衡量样本集纯度的常用指标:
\[Ent(D) = -\sum_{k=1}^{|\mathcal{Y}|}p_klog_2p_k\]| 一定要记得最前面的负号!!!其中 $ | \mathcal{Y} | $ 为类别集合,$p_k$ 为该类样本占样本总数的比例。 |
信息熵越大,表示样本集的混乱程度越高,纯度越低。
信息增益
信息增益(information gain)是ID3算法采用的选择准则,定义如下:
\[Gain(D,a) = Ent(D) - \sum_{v=1}^{V}\frac{|D^v|}{|D|}Ent(D^v)\]它描述的是按某种属性划分后纯度的提升,信息增益越大,代表用属性 $a$ 进行划分所获得的纯度提升越大。其中 $V$ 表示属性 $a$ 的属性值集合,$D^v$ 表示属性值为 $v$ 的数据子集。求和项也称为条件熵,我们可以理解为它是先求出每个数据子集的信息熵,然后按每个数据子集占原数据集的比例来赋予权重,比例越大,对提升纯度的帮助就越大。
多个属性都取得最大的信息增益时,任选一个即可。
信息增益又称为互信息(Mutual information)。
- 一个连续变量X的不确定性,用方差Var(X)来度量
- 一个离散变量X的不确定性,用熵H(X)来度量
- 两个连续变量X和Y的相关度,用协方差或相关系数来度量
- 两个离散变量X和Y的相关度,用互信息I(X;Y)来度量(直观地,X和Y的相关度越高,X对分类的作用就越大)
(信息)增益率
增益率(gain ratio)是C4.5算法采用的选择准则,定义如下:
\[Gain\_ratio(D,a) = \frac{Gain(D,a)}{IV(a)}\]其中,
\[IV(a) = -\sum_{v=1}^V\frac{|D^v|}{|D|}log_2\frac{|D^v|}{|D|}\]一定要记得最前面的负号!!!IV称为属性的固有值(intrinsic value),它的定义和信息熵是类似的,信息熵衡量的是样本集在类别上的混乱程度,而固有值衡量的是样本集在某个属性上的混乱程度。固有值越大,则该属性混乱程度越高,可能的取值越多。
之所以要定义增益率是为了避免模型过份偏好用取值多的属性作划分。这是使用信息增益作准则非常容易陷入的误区,比方说每个样本都有一个“编号”属性,这个属性的条件熵肯定是最小的,但如果选择了该属性作为根节点,那么构建出的决策树就没有任何意义了,因为这个模型根本不具备泛化性能。
C4.5并非直接选择增益率最高的属性,它使用了一个启发式:先从属性集中找到信息增益高于平均水平的属性作为候选,然后再比较这些候选属性的增益率,从中选择增益率最高的。
基尼指数
基尼指数(Gini index)是CART算法采用的选择准则,定义如下:
基尼值:
\[Gini(D) = \sum_{k=1}^{|\mathcal{Y}|}\sum_{k' \neq k}p_kp_{k'}\\ =1-\sum_{k=1}^{|\mathcal{Y}|}p_k^2\]基尼指数:
\[Gini\_index(D,a) = \sum_{v=1}^{V}\frac{|D^v|}{|D|}Gini(D^v)\]基尼值是另一种衡量样本集纯度的指标。反映的是从一个数据集中随机抽取两个样本,其类别标志不同的概率。
基尼值越小,样本集的纯度越高。
由基尼值引伸开来的就是基尼指数这种准则了,基尼指数越小,表示使用属性 $a$ 划分后纯度的提升越大。
3.决策树的剪枝
剪枝是决策树停止分支的方法之一,剪枝有分预先剪枝和后剪枝两种。预先剪枝是在树的生长过程中设定一个指标,当达到该指标时就停止生长,这样做容易产生“视界局限”,就是一旦停止分支,使得节点N成为叶节点,就断绝了其后继节点进行“好”的分支操作的任何可能性。不严格的说这些已停止的分支会误导学习算法,导致产生的树不纯度降差最大的地方过分靠近根节点。后剪枝中树首先要充分生长,直到叶节点都有最小的不纯度值为止,因而可以克服“视界局限”。然后对所有相邻的成对叶节点考虑是否消去它们,如果消去能引起令人满意的不纯度增长,那么执行消去,并令它们的公共父节点成为新的叶节点。这种“合并”叶节点的做法和节点分支的过程恰好相反,经过剪枝后叶节点常常会分布在很宽的层次上,树也变得非平衡。后剪枝技术的优点是克服了“视界局限”效应,而且无需保留部分样本用于交叉验证,所以可以充分利用全部训练集的信息。但后剪枝的计算量代价比预剪枝方法大得多,特别是在大样本集中,不过对于小样本的情况,后剪枝方法还是优于预剪枝方法的。
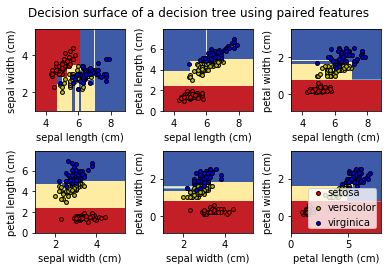
scikit-learn示例
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
n_classes = 3
plot_colors = "ryb"
plot_step = 0.02
iris = load_iris()
for pairidx, pair in enumerate([[0, 1], [0, 2], [0, 3],
[1, 2], [1, 3], [2, 3]]):
# 同样只取两个特征
X = iris.data[:, pair]
y = iris.target
clf = DecisionTreeClassifier().fit(X, y)
# 画出分类界线
plt.subplot(2, 3, pairidx + 1)
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, plot_step),
np.arange(y_min, y_max, plot_step))
plt.tight_layout(h_pad=0.5, w_pad=0.5, pad=2.5)
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
cs = plt.contourf(xx, yy, Z, cmap=plt.cm.RdYlBu)
plt.xlabel(iris.feature_names[pair[0]])
plt.ylabel(iris.feature_names[pair[1]])
# 画出训练数据的点
for i, color in zip(range(n_classes), plot_colors):
idx = np.where(y == i)
plt.scatter(X[idx, 0], X[idx, 1], c=color, label=iris.target_names[i],
cmap=plt.cm.RdYlBu, edgecolor='black', s=15)
plt.suptitle("Decision surface of a decision tree using paired features")
plt.legend(loc='lower right', borderpad=0, handletextpad=0)
plt.axis("tight")
plt.show()
版权声明:本文为博主原创文章,转载请注明出处。 旭日酒馆