概念
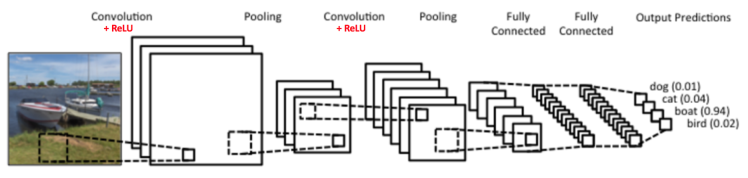
CNN主要用于图像识别等应用,图中是一个图形识别的CNN模型。最左边的船的图像就是我们的输入层,计算机理解为输入若干个矩阵。
接着是卷积层(Convolution Layer)。卷积层的激活函数使用的是ReLU:ReLU(x)=max(0,x) 。在卷积层后面是池化层(Pooling layer),这个也是CNN特有的。需要注意的是,池化层没有激活函数。
卷积层+池化层的组合可以在隐藏层出现很多次,上图中出现两次。而实际上这个次数是根据模型的需要而来的。当然我们也可以灵活使用使用卷积层+卷积层,或者卷积层+卷积层+池化层的组合,这些在构建模型的时候没有限制。但是最常见的CNN都是若干卷积层+池化层的组合,如上图中的CNN结构。
在若干卷积层+池化层后面是全连接层(Fully Connected Layer, 简称FC),全连接层其实就是DNN结构,只是输出层使用了Softmax激活函数来做图像识别的分类。
卷积
-
微积分中卷积的表达式为:$S(t)=\int x(t-a)w(a)da$
-
离散形式是:$S(t)=\sum_{a} x(t-a)w(a)$
-
矩阵形式:s(t)=(X∗W)(t),其中星号表示卷积。
在CNN中,卷积公式和严格意义数学中的定义稍有不同,比如对于二维的卷积,定义为:
\[s(i,j)=(X*W)(i,j)=\sum_{m}\sum_{n}x(i+m,j+n)w(m,n)\]其中,我们叫W为我们的卷积核,而X则为我们的输入。如果X是一个二维输入的矩阵,而W也是一个二维的矩阵。但是如果X是多维张量,那么W也是一个多维的张量。
卷积层
假如是对图像卷积,其实就是对输入的图像的不同局部的矩阵和卷积核矩阵各个位置的元素相乘,然后相加得到。

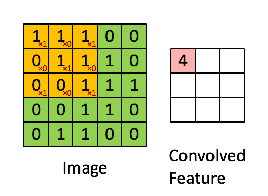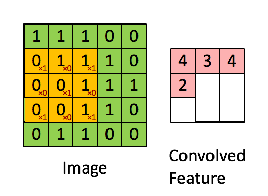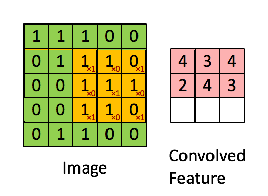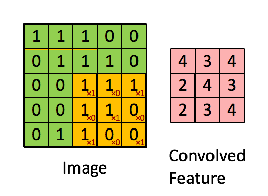
池化层
所谓的池化就是对输入张量的各个子矩阵进行压缩。假如是2x2的池化,那么就将子矩阵的每2x2个元素变成一个元素,如果是3x3的池化,那么就将子矩阵的每3x3个元素变成一个元素,这样输入矩阵的维度就变小了。
要想将输入子矩阵的每nxn个元素变成一个元素,那么需要一个池化标准。常见的池化标准有2个,MAX或者是Average。即取对应区域的最大值或者平均值作为池化后的元素值。
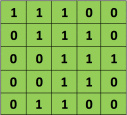
下面这个例子采用取最大值的池化方法。同时采用的是2x2的池化。步幅为2。
首先对红色2x2区域进行池化,由于此2x2区域的最大值为6.那么对应的池化输出位置的值为6,由于步幅为2,此时移动到绿色的位置去进行池化,输出的最大值为8.同样的方法,可以得到黄色区域和蓝色区域的输出值。最终,我们的输入4x4的矩阵在池化后变成了2x2的矩阵。进行了压缩。
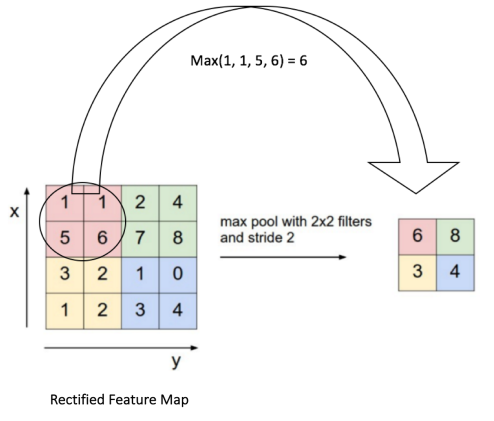
常见CNN模型
-
LeNet5
-
Dan Ciresan Net
-
AlexNet
-
Overfeat
-
VGG
-
ResNet
-
Network in Network
代码示例
#CNN
import torch
from torch import nn, optim
import torch.nn.functional as F
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
# 定义超参数
batch_size = 128
learning_rate = 1e-2
num_epoches = 5
def to_np(x):
return x.cpu().data.numpy()
# 下载训练集 MNIST 手写数字训练集
train_dataset = datasets.MNIST(
root='./data', train=True, transform=transforms.ToTensor(), download=True)
test_dataset = datasets.MNIST(
root='./data', train=False, transform=transforms.ToTensor())
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# 定义 CNN 模型
class Cnn(nn.Module):
def __init__(self, in_dim, n_class):
super(Cnn, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_dim, 6, 3, stride=1, padding=1),
nn.ReLU(True),
nn.MaxPool2d(2, 2),
nn.Conv2d(6, 16, 5, stride=1, padding=0),
nn.ReLU(True), nn.MaxPool2d(2, 2))
self.fc = nn.Sequential(
nn.Linear(400, 120), nn.Linear(120, 84), nn.Linear(84, n_class))
def forward(self, x):
out = self.conv(x)
out = out.view(out.size(0), -1)
out = self.fc(out)
return out
model = Cnn(1, 10) # 图片大小是28x28
use_gpu = torch.cuda.is_available() # 判断是否有GPU加速
if use_gpu:
model = model.cuda()
# 定义loss和optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=learning_rate)
logger = Logger('./logs')
# 开始训练
for epoch in range(num_epoches):
print('epoch {}'.format(epoch + 1))
print('*' * 10)
running_loss = 0.0
running_acc = 0.0
for i, data in enumerate(train_loader, 1):
img, label = data
if use_gpu:
img = img.cuda()
label = label.cuda()
img = Variable(img)
label = Variable(label)
# 向前传播
out = model(img)
loss = criterion(out, label)
running_loss += loss.data[0] * label.size(0)
_, pred = torch.max(out, 1)
num_correct = (pred == label).sum()
accuracy = (pred == label).float().mean()
running_acc += num_correct.data[0]
# 向后传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
# ========================= Log ======================
step = epoch * len(train_loader) + i
if i % 300 == 0:
print('[{}/{}] Loss: {:.6f}, Acc: {:.6f}'.format(
epoch + 1, num_epoches, running_loss / (batch_size * i),
running_acc / (batch_size * i)))
print('Finish {} epoch, Loss: {:.6f}, Acc: {:.6f}'.format(
epoch + 1, running_loss / (len(train_dataset)), running_acc / (len(
train_dataset))))
model.eval()
eval_loss = 0
eval_acc = 0
for data in test_loader:
img, label = data
if use_gpu:
img = Variable(img, volatile=True).cuda()
label = Variable(label, volatile=True).cuda()
else:
img = Variable(img, volatile=True)
label = Variable(label, volatile=True)
out = model(img)
loss = criterion(out, label)
eval_loss += loss.data[0] * label.size(0)
_, pred = torch.max(out, 1)
num_correct = (pred == label).sum()
eval_acc += num_correct.data[0]
print('Test Loss: {:.6f}, Acc: {:.6f}'.format(eval_loss / (len(
test_dataset)), eval_acc / (len(test_dataset))))
print()
# 保存模型
torch.save(model.state_dict(), './cnn.pth')
epoch 1
**********
[1/5] Loss: 2.259069, Acc: 0.281615
Finish 1 epoch, Loss: 2.080241, Acc: 0.391950
Test Loss: 1.131448, Acc: 0.707400
epoch 2
**********
[2/5] Loss: 0.648300, Acc: 0.813229
Finish 2 epoch, Loss: 0.567954, Acc: 0.834383
Test Loss: 0.365122, Acc: 0.891900
epoch 3
**********
[3/5] Loss: 0.359592, Acc: 0.892865
Finish 3 epoch, Loss: 0.346367, Acc: 0.896433
Test Loss: 0.291786, Acc: 0.911000
epoch 4
**********
[4/5] Loss: 0.287946, Acc: 0.913281
Finish 4 epoch, Loss: 0.280169, Acc: 0.915217
Test Loss: 0.247032, Acc: 0.927300
epoch 5
**********
[5/5] Loss: 0.231482, Acc: 0.930339
Finish 5 epoch, Loss: 0.230984, Acc: 0.929950
Test Loss: 0.189043, Acc: 0.945500
版权声明:本文为博主原创文章,转载请注明出处。 旭日酒馆